
Software Engineering: A Modern Approach
9 Refactoring 🔗
I’m not a great programmer; I’m just a good programmer with great habits. – Kent Beck
This chapter begins in Section 9.1 with an introduction to refactorings, which are modifications made to a program to make it easier to understand and modify. Section 9.2 presents a series of refactoring operations, including code examples, some of which are derived from real refactorings performed on open-source projects. In Section 9.3, we discuss various aspects of the practice of refactoring, including the importance of having a robust unit test suite. Section 9.4 explores the support provided by IDEs for automated refactoring. Finally, Section 9.5 introduces a list of code smells, which are indicators that a particular code structure may benefit from refactoring.
9.1 Introduction 🔗
As discussed in the previous chapter, software, like any engineering product, needs to be tested. Similarly, software also requires maintenance. In fact, as mentioned in Chapter 1, there are various types of maintenance that can be performed on software systems. For instance, when a bug is detected, we must apply corrective maintenance. When users or the Product Owner request a new feature, we need to conduct evolutionary maintenance. When a business rule or a technology used by the system changes, we must allocate time to perform adaptive maintenance.
Furthermore, software systems, like living beings, also age. In the early 1970s, Meir Lehman, while working at IBM, studied this phenomenon and subsequently formulated a set of empirical laws concerning aging, internal quality, and the evolution of software systems, which became known as the Software Evolution Laws or simply Lehman’s Laws. The first two laws formulated by Lehman were:
A system must be continuously adapted to its environment. This process should continue until it becomes more advantageous to replace the system with a new one.
As a system undergoes maintenance, its internal complexity increases unless deliberate efforts are made to reduce this complexity.
Lehman’s first law justifies the need for adaptive and evolutionary
maintenance. It also indicates that systems can die
, meaning
there may come a time when it is more advantageous to replace a system
with a new one. The second law states that maintenance makes the code
and internal structure of a system more complex and harder to maintain
over time. In other words, a system’s internal quality naturally
deteriorates as it undergoes maintenance and evolution. However, this
law also includes a caveat: this deterioration can be prevented if
specific work is done to maintain internal quality. Today, this work is
called refactoring.
Refactorings are code transformations that improve a system’s maintainability without affecting its behavior. To explain this definition, let’s divide it into three parts. First, when the definition mentions code transformations, it refers to modifications in the code, such as splitting a function into two, renaming a variable, moving a function to another class, or extracting an interface from a class, among others. Next, the definition mentions the goal of such transformations: to improve the maintainability of the system, which means to improve its modularity, design, or architecture; enhance its testability; and make the code more readable and easier to understand and modify, among other benefits. Finally, a restriction is set: it is not worth improving maintainability at the cost of changing the program’s results. In other words, refactoring must ensure that the system works exactly as it did before the transformation. Alternatively, we can say that refactorings must preserve the system’s behavior.
However, in the 1970s and 1980s when Lehman’s Laws were formulated, the term refactoring was not yet used. One of the first recorded uses of this term occurred in 1992, in a doctoral thesis defended by William Opdyke at the University of Illinois (link). In 1999, refactoring, now known by this name, was included among the programming practices advocated by Extreme Programming. In the first edition of the XP book, it was recommended that developers perform refactorings with the goal of restructuring their systems to remove duplication, improve communication among developers, and simplify or make the design more flexible.
In 2000, Martin Fowler released the first edition of a book dedicated to refactoring, which was very successful and contributed to popularizing this practice. One of the reasons for this success was that the book presented a catalog with dozens of refactorings. In a style resembling a catalog of design patterns (studied in Chapter 6), the presentation of the refactorings began by naming them, thus helping to create a vocabulary for refactoring. Fowler also presented the mechanics of each refactoring, included code examples, and discussed the benefits and potential drawbacks.
In his book, Fowler mentions Kent Beck’s phrase that opens this
chapter and emphasizes the importance of following good programming
habits,
which are essential for maintaining a program’s health and
ensuring it continues to provide value over the years. As a result,
developers should perform not only corrective, adaptive, and
evolutionary maintenance but also frequent refactorings to ensure the
system’s maintainability.
Note: The term refactoring has become common in software engineering. Therefore, it is sometimes used to indicate improvements in other non-functional requirements beyond maintainability. For example, we often hear developers say they will refactor their code to improve performance, introduce concurrency, or improve the usability of the interface. However, in this book, we use the term in its original, restricted sense—referring only to modifications that improve the maintainability of the source code.
9.2 Examples of Refactorings 🔗
In this section, we will present some widely used refactorings. For each refactoring, we will present its name, motivation, and implementation mechanics. Furthermore, we will illustrate them with examples from real refactorings performed in open-source projects.
9.2.1 Extract Method 🔗
Extract Method is one of the most important refactorings, as it aims
to extract a piece of code from method f and move it to a
new method g. Subsequently, f will include a
call to g. The following example illustrates this
refactoring. First, here’s the code before the refactoring:
void f() {
... // A
... // B
... // C
}And here’s the code after extracting method g:
void g() { // extracted method
... // B
}
void f() {
... // A
g();
... // C
}
There are also variations in the extraction mechanics. For instance,
it is possible to extract multiple methods, denoted as g1,
g2, …, gn, from a single method f
all at once. Additionally, we can extract the same code g
from multiple methods, denoted as f1, f2, …,
fn. In this case, the extraction is used to eliminate
code duplication, since the code in g is
repeated in several methods.
To perform an Extract Method refactoring, we may need to pass parameters to the new method. This is necessary, for example, if the extracted method uses local variables from the original method. Additionally, the extracted method should return values if they are used later by the original method. As a last example, if local variables are only used in the extracted code, we should extract their declarations as well.
Extract Method is often referred to as the Swiss Army knife
of
refactorings due to its versatility and wide range of applications. For
instance, it can be employed to break down a large method into smaller
ones, each serving a specific goal that is reflected in its name. This
approach also enhances the comprehensibility of the original method, as
its body after the refactoring consists of only a sequence of calls. An
example is provided below, and other applications of Extract Method are
discussed in the next section.
Example: Here, we provide a real example of Extract
Method from an Android system. This system has an onCreate
method, which uses SQL commands to create the database tables used by
the system. The code for the initial version of
onCreate—after a few edits, simplifications, and removal of
comments—is presented below. The original method exceeded 200 lines.
void onCreate(SQLiteDatabase database) {// before extraction
// creates table 1
database.execSQL("CREATE TABLE " +
CELL_SIGNAL_TABLE + " (" + COLUMN_ID +
" INTEGER PRIMARY KEY AUTOINCREMENT, " + ...
database.execSQL("CREATE INDEX cellID_index ON " + ...);
database.execSQL("CREATE INDEX cellID_timestamp ON " +...);
// creates table 2
String SMS_DATABASE_CREATE = "CREATE TABLE " +
SILENT_SMS_TABLE + " (" + COLUMN_ID +
" INTEGER PRIMARY KEY AUTOINCREMENT, " + ...
database.execSQL(SMS_DATABASE_CREATE);
String ZeroSMS = "INSERT INTO " + SILENT_SMS_TABLE +
" (Address,Display,Class,ServiceCtr,Message) " +
"VALUES ('"+ ...
database.execSQL(ZeroSMS);
// creates table 3
String LOC_DATABASE_CREATE = "CREATE TABLE " +
LOCATION_TABLE + " (" + COLUMN_ID +
" INTEGER PRIMARY KEY AUTOINCREMENT, " + ...
database.execSQL(LOC_DATABASE_CREATE);
// more than 200 lines, creating other tables
}
To enhance this method’s clarity, a developer decided to perform
seven Extract Method refactorings. Each extracted method became
responsible for creating one of the tables. By examining the names of
these methods, we can easily infer which tables they create. After these
extractions, the onCreate method only calls the extracted
methods, as shown below. The method’s size has been reduced from over
200 lines to just seven lines. It’s also worth noting that each
extracted method has a parameter representing the database where the
tables should be created.
public void onCreate(SQLiteDatabase database) {
createCellSignalTable(database);
createSilentSmsTable(database);
createLocationTable(database);
createCellTable(database);
createOpenCellIDTable(database);
createDefaultMCCTable(database);
createEventLogTable(database);
}Extract Method Motivations 🔗
In 2016, along with Danilo Silva and Prof. Nikolaos Tsantalis from Concordia University in Montreal, we conducted a study with GitHub developers to uncover their motivations for performing refactorings (link). In this study, we identified 11 distinct motivations for method extraction, as shown in the following table.
| Motivations for Extract Method | Occurrences |
|---|---|
| Extracting a method that will be called by other methods | 43 |
| Introducing an alternative signature for an existing method | 25 |
| Breaking a method into smaller parts to improve understanding | 21 |
| Extracting a method to remove code duplication | 15 |
| Extracting a method to facilitate the implementation of a new feature or to fix a bug | 14 |
| Extracting a method with a better name or fewer parameters | 6 |
| Extracting a method to test its code | 6 |
| Extracting a method that will be overridden by subclasses | 4 |
| Extracting a method to allow recursive calls | 2 |
| Extracting a method that will work as a factory | 1 |
| Extracting a method that will run on a thread | 1 |
Analyzing this table, we can see that the primary motivation was code
reuse. Developers often come across a piece of code they need, only to
find it is already implemented within a method f. To make
this code accessible, they perform an Extract Method, creating a new
method g. This allows them to call g in the
code they are working on. Here’s an example of how one developer
reported this motivation for extracting a method:
These refactorings were made because of code reusability. I needed to use the same code in a new method. I always try to reuse code, because when there’s a lot of code redundancy, it gets overwhelmingly more complicated to work with the code in the future, because when something changes in code that is duplicated somewhere, it usually needs to be changed there also.
As seen in the previous table, the second most frequent motivation was introducing an alternative signature for a method. An example is shown below, involving a method that logs a string to a file. We first show the code before the refactoring:
void log(String msg) {
// saves msg to file
}The developer decided to provide an alternative version of this
method with a boolean parameter, indicating whether the string should
also be printed on the console. Here is the code after extracting this
second log method:
void log(String msg, boolean console) {
if (console)
System.out.println(msg);
// saves msg to a file
}
void log(String msg) {
log(msg, false);
}It’s worth noting that, technically, this transformation qualifies as
an Extract Method. Initially, the log(String) code was
extracted to log(String, boolean), creating a new method.
Subsequently, minor adjustments were made to the extracted code,
including the addition of an if statement. Such adjustments
are common and do not disqualify the transformation as a method
extraction.
9.2.2 Inline Method 🔗
This refactoring operates in the opposite direction of Extract Method. Consider a method with only one or two lines of code that is rarely called. Thus, the benefits offered by this method, both in terms of reuse and organization of the code, are minimal. Consequently, it can be removed from the system, and its body can be incorporated into the call sites. It’s important to note that Inline Method is a less common and less significant refactoring compared to Extract Method.
Example: The following code shows an example of
Inline Method. First, here is the code before inlining. We can observe
that the writeContentToFile method has a single line of
code and is called only once by the write method.
private void writeContentToFile(final byte[] revision) {
getVirtualFile().setBinaryContent(revision);
}
private void write(byte[] revision) {
VirtualFile virtualFile = getVirtualFile();
...
if (document == null) {
writeContentToFile(revision);
}
...
}
The developers decided to remove the writeContentToFile
method and inline its body at the single call site. Here is the code
after the refactoring:
private void write(byte[] revision) {
VirtualFile virtualFile = getVirtualFile();
...
if (document == null) {
virtualFile.setBinaryContent(revision); // after inline
}
...
}9.2.3 Move Method 🔗
It is not uncommon to find a method implemented in the wrong class.
This occurs when a method f is located in class A, but it
uses more services from class B. For instance, it may have more
dependencies on elements of B than on elements of its original class. In
such cases, moving f to B should be considered. This
refactoring can improve the cohesion of A, reduce the coupling between A
and B, and ultimately make both classes easier to understand and
modify.
Due to these characteristics, Move Method is one of the refactorings with the highest potential to improve modularity. Since its effects extend beyond a single class, this refactoring can positively impact the system’s architecture, ensuring that methods are placed in the appropriate classes from both functional and architectural viewpoints.
Example: Consider the code of an IDE. In this code,
we have a class called PlatformTestUtil, which is
responsible for a specific feature provided by the IDE. The details of
this feature are not important for our discussion here, so we will omit
them. For our purposes, the key point is that this class has a method
called averageAmongMedians (see below), which calculates
the average of the medians stored in an array. However, this method has
no relationship to the other methods in PlatformTestUtil.
For example, it neither calls methods nor uses attributes of
PlatformTestUtil. In summary, it is independent of the rest
of the class.
class PlatformTestUtil {
...
public static long averageAmongMedians(long[] time, int part) {
int n = time.length;
Arrays.sort(time);
long total = 0;
for (int i= n/2-n/part/2; i< n/2+n/part/2; i++) {
total += time[i];
}
int middlePartLength = n/part;
return middlePartLength == 0 ? 0 :total / middlePartLength;
}
...
}Therefore, the developers of this system decided to move
averageAmongMedians to a class called
ArrayUtil, whose purpose is to provide general functions
for array manipulation. Thus, this class is more suited to the service
provided by averageAmongMedians. After the Move Method, the
existing calls to averageAmongMedians should be updated, as
shown in the following figure.

As observed in this figure, this update was straightforward because
averageAmongMedians is a static method. Therefore, only the
class name needed to be changed at each call site.
However, in other cases, updating the calls after a Move Method refactoring may not be straightforward. This occurs when there are no references to objects of the target class at the call sites. In such cases, one possible solution is to leave a simple implementation of the method in the original class, which forwards the calls to the new method’s class. This way, the existing calls do not need to be updated. An example is shown below. First, here is the original code:
class A {
B b = new B();
void f() { ... }
}
class B { ... }
class Client {
A a = new A();
void g() {
a.f();
...
}
}And here is the code after the refactoring:
class A {
B b = new B();
void f() {
b.f(); // forwards the call to B
}
}
class B { // f was moved from A to B
void f() { ... }
}
class Client {
A a = new A();
void g() {
a.f(); // no changes required
...
}
}Note that f was moved from class A to class B. However,
in class A, we left a version of the method that simply forwards the
call to B. Thus, the Client class does not require any
updates.
When the Move Method refactorings occur within the same class
hierarchy, they receive special names. For example, when we move a
method from a subclass to a superclass, it is called a Pull Up
Method. To illustrate, consider a scenario where the same
method f is implemented in subclasses B1 and
B2. In this case, we can avoid the duplicated
implementation by pulling up
each implementation to the
superclass A, as shown below.

Conversely, when a method is moved down the class hierarchy, from a
superclass to a subclass, it is called a Push Down
Method refactoring. For instance, if a method f is
implemented in superclass A, but it is relevant to only one
subclass, say B1, we can push down
its
implementation to B1, as shown in the following figure.

To conclude, refactoring operations can also be performed in
sequence. For example, consider class A with a method
f:
class A {
B b = new B();
void f() {
S1;
S2;
}
}
class B { ... }First, from f, we extract a method g
containing the statement S2:
class A {
B b = new B();
void g() { // extracted method
S2;
}
void f() {
S1;
g();
}
}
class B { ... }Next, we move g to class B, as shown
below:
class A {
B b = new B();
void f() {
S1;
b.g();
}
}
class B {
void g() { // moved method
S2;
}
}9.2.4 Extract Class 🔗
This refactoring is recommended when a class A has many responsibilities and attributes. If some of these attributes are related, they can be grouped in another location. In other words, they can be extracted to form a new class B. After the extraction, we should declare an attribute of type B in class A.
Example: Let’s consider the class
Person shown below. In addition to other attributes, which
have been omitted from the example, it stores the person’s phone
numbers, including area code and number.
class Person {
String areaCode;
String phone;
String alternativeAreaCode;
String alternativePhone;
...
}A new class Phone can be extracted from
Person, as shown below. After the refactoring,
Person receives two attributes of this new type.
class Phone { // extracted class
String areaCode;
String number;
}
class Person {
Phone phone;
Phone alternativePhone;
...
}A similar refactoring is called Extract Interface.
For example, consider a library with classes LinkedList and
ArrayList. From these classes, we can extract an interface
List, with the methods common to both. Then, the library’s
clients can apply the Prefer Interfaces to Concrete Classes
design principle, which we studied in Chapter 5.
9.2.5 Renaming 🔗
There’s a provocative phrase attributed to Phil Karlton that says
There are only two hard things in computer science: cache
invalidation and naming things.
As naming is hard, we often have to
rename code elements, including variables, functions, methods,
parameters, attributes, and classes. This may happen because the initial
name of the element was not a good choice. Alternatively, the
responsibility of an element may change over time, making its name
outdated. In both cases, it is recommended to perform one of the most
popular refactorings: renaming—that is, giving a more
appropriate and meaningful name to a code element.
However, the most complex part of this refactoring is not changing
the name of the element, but updating the parts of the code where it is
referenced. For example, if a method f is renamed to
g, all calls to f must be updated. In cases
where f is widely used, it might be beneficial to extract
its body to a new method, with the new name, and keep the old method as
deprecated.
To illustrate, suppose we have the following method
f:
void f () {
// A
}Next, we show the code after renaming f to
g. Note that we have kept a deprecated version of
f in the code, which simply calls g.
void g() { // new name
// A
}
@Deprecated
void f() { // old name
g(); // forwards call to new method
}Deprecation is a mechanism provided by programming languages to
indicate that a code element is outdated and should no longer be used.
When the compiler detects a piece of code using a deprecated element, it
issues a warning. As illustrated in the previous example, the method
f was not simply renamed to g. Instead, first,
a method g was created with f’s original code.
Then, f was deprecated, and its code was modified to only
call g.
This deprecation-based strategy makes renaming safer, as it does not
require updating all the calls to f at once. Instead, it
gives clients time to adapt to the change and start using the new name.
Indeed, refactorings—even the simplest ones, like renaming—should be
performed in small steps or baby steps
to avoid introducing bugs
into working code.
9.2.6 Other Refactorings 🔗
The refactorings presented earlier are those with the highest potential for improving a system’s design, as they involve changes with a global scope, such as Move Method or Extract Class. However, some refactorings have a narrower scope and improve, for example, the internal implementation of a single method. In this section, we briefly describe some of these refactorings.
Extract Variable is used to simplify expressions and make them easier to read and understand. Here’s an example:
x1 = (-b + sqrt(b*b - 4*a*c)) / (2*a);This code can be refactored to:
delta = b*b - 4*a*c; // extracted variable
x1 = (-b + sqrt(delta)) / (2*a);
In this refactoring, a new variable delta was created
and initialized with part of the larger expression. As a result, the
expression, after the refactoring, became shorter and easier to
understand.
Remove Flag is a refactoring that recommends using
statements like break or return instead of
control variables (or flags). Here’s a code example:
boolean search(int x, int[]a) {
boolean found = false;
int i = 0;
while ((i < a.length) && (!found)) {
if (a[i] == x)
found = true;
i++;
}
return found;
}This code can be refactored as follows:
boolean search(int x, int[] a) {
for (int i = 0; i < a.length; i++)
if (a[i] == x)
return true;
return false;
}After this refactoring, the function is shorter and cleaner, thanks
to the use of a return statement to exit immediately once
the searched value is found. As a result, the flag variable
found has been removed.
There are also refactorings designed to simplify conditional
statements. One of them is called Replace Conditional with
Polymorphism. To understand it, consider a switch
statement that returns the value of a student’s research grant,
depending on the student’s type:
switch (student.getType()) {
case "undergraduate":
grant = 750;
break;
case "master":
grant = 2000;
break;
case "phd":
grant = 3000;
break;
}In object-oriented languages, this statement can be refactored to a single line of code:
double grant = student.getGrant();
In the refactored version, the getType() method of
Student is no longer needed and can be removed. However, we
must implement the getGrant() method in the
Student’s subclasses—for example,
UndergraduateStudent, MasterStudent, and
PhDStudent. In the Student superclass, this
method must be declared as abstract, requiring it to have only a
signature, without a body.
Remove Dead Code involves deleting methods, classes, variables, or attributes that are no longer used. For example, in the case of a method, there might be no calls to it anymore. In the case of a class, it might not be instantiated or inherited by any other classes. In the case of an attribute, it might not be used within the class body, nor in subclasses or in other classes. This may seem uncommon, but in large systems, maintained over years by dozens or even hundreds of developers, considerable amounts of unused code often accumulate.
9.3 Refactoring Practice 🔗
After describing various refactorings in the previous section, let’s now discuss how to implement the practice of refactoring in real software projects.
First, successful refactoring depends on the existence of good tests, particularly unit tests. Without tests, making changes in a system becomes risky, especially when these changes do not add new features or fix bugs, as is the case with refactorings. John Ousterhout emphasizes the importance of tests during refactoring activities (link, Section 19.3):
Tests, particularly unit tests, play an important role in design because they facilitate refactoring. Without a test suite, it’s dangerous to make major structural changes to a system. […] As a result, developers avoid refactoring in a system without good test suites; they try to minimize the number of code changes for each new feature or bug fix, which means that complexity accumulates and design mistakes don’t get corrected.
The second important issue concerns the timing of refactoring. There are two main approaches to refactoring: opportunistic and strategic.
Opportunistic refactorings are carried out during a programming task when developers find that a piece of code is not well implemented and could be improved. This can happen when correcting a bug or implementing a new feature. For instance, during these tasks, we might notice that a method’s name is unclear, a method is too long and difficult to understand, a conditional statement is too complex, or some code is no longer used. Whenever we detect such problems with a piece of code, we should refactor it immediately. For example, suppose you will spend an hour implementing a new feature. In this case, it is desirable to invest part of that time—perhaps 20% or more—in refactoring. Kent Beck has an interesting quote about opportunistic refactorings:
For each desired change, make the change easy (warning: this may be hard), then make the easy change.
The underlying premise of this recommendation is that we may be
struggling to implement a change precisely because the code is not
prepared to accommodate it. Therefore, we should first take a step
back
and refactor the code to make the change easier. Once this is
done, we can then take two steps forward and more easily implement the
assigned change.
Most refactorings are opportunistic, but it is also possible to have planned refactorings. These typically involve time-consuming and complex changes that cannot be accommodated within a typical development task. Instead, they should be carried out in scheduled and dedicated sessions. For instance, such refactorings might involve breaking a package into two or more subpackages. Another example occurs when teams have neglected the practice of refactoring for a long time. In such cases, with numerous pending refactorings, it’s better to schedule them for a specific time period.
9.4 Automated Refactorings 🔗
Today, most IDEs provide support for automated refactorings as follows: developers select the block of code they want to refactor and choose the desired refactoring operation. The IDE then executes the operation automatically. The following figures illustrate an automated renaming in an IDE:

To perform the operation, the developer selects the Rename Symbol option from the context menu:
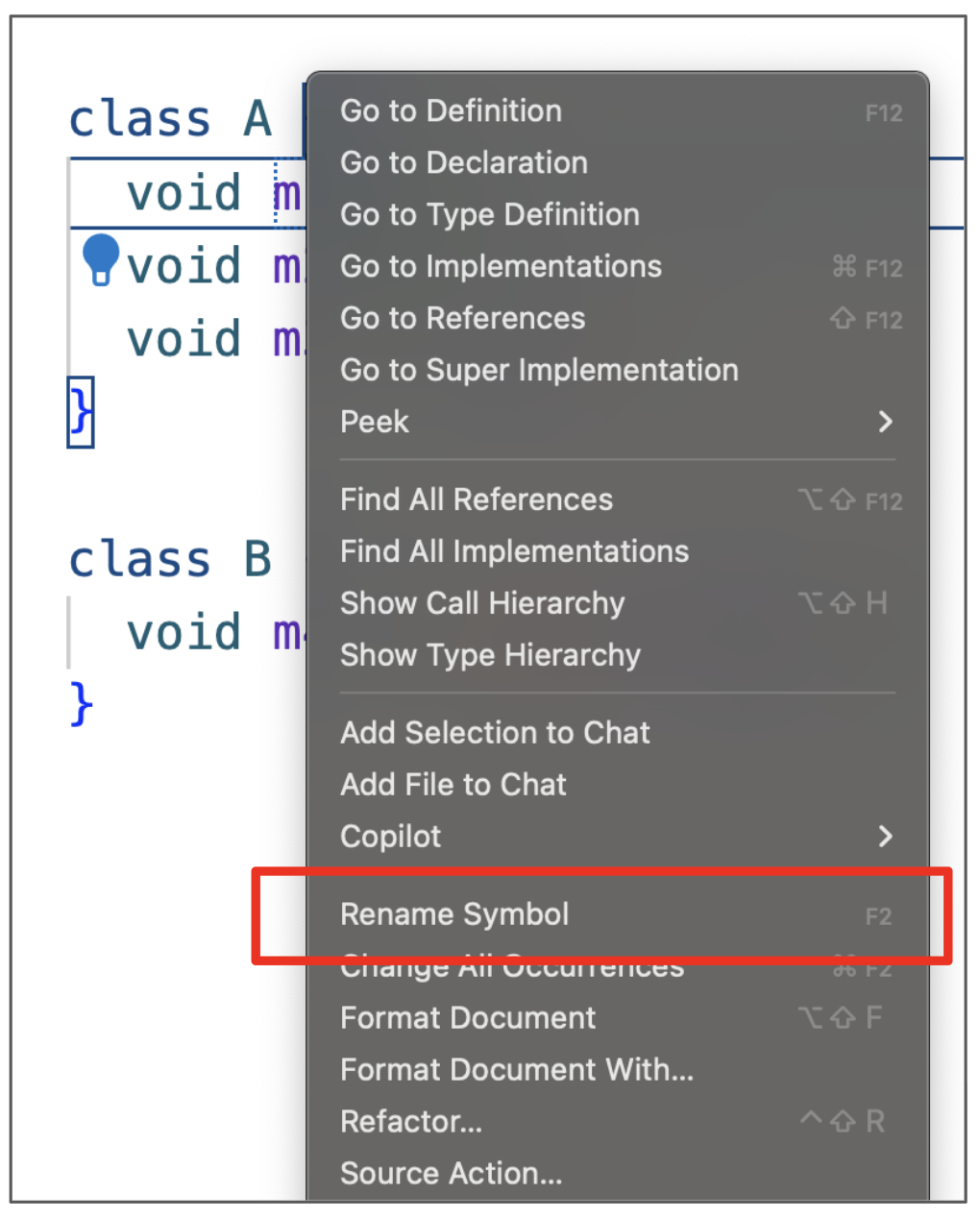
The IDE then prompts the developer to enter the new method name (see the following figure).

Finally, the IDE executes the refactoring:

As we can see, the method has been renamed to m11.
Furthermore, the calls in m3 and m4 have been
updated to use this new name.
Although it is called automated refactoring, the example shows that developers are still responsible for specifying the code to refactor and the operation to perform. Moreover, developers must provide specific information about the refactoring, such as the new name in the case of renaming. Only after these inputs are provided does the IDE automate the refactoring process.
Before applying the refactoring, the IDE checks whether its
preconditions are satisfied, i.e., that the refactoring
will not cause a compilation error or change the program’s behavior. In
the previous example, if the user attempts to rename m1 to
m2, the IDE would inform them that this refactoring cannot
be performed, as the class already has a method named
m2.
9.4.1 Checking Refactoring Preconditions 🔗
The task of checking a refactoring’s preconditions is, in most cases,
not simple. To illustrate the complexity of this task, let’s examine a
small Java program proposed by Friedrich Steimann and Andreas Thies (link). The
program below has two classes, A and B,
implemented in separate files but belonging to the same package
P1. Therefore, the call to m("abc") in the
first file executes the m(String) method in class
B.
// File A.java
package P1;
public class A {
void n() {
new B().m("abc"); // executes m(String) from B
}
}
// File B.java
package P1;
public class B {
public void m(Object o) {...}
void m(String s) {...}
}
Suppose class B is moved to a new package, such as
P2:
// File B.java
package P2; // new package for B
public class B {
public void m(Object o) {...}
void m(String s) {...}
} Although it might seem harmless, this move changes the behavior of
the program. In the new version, the call to m("abc")
results in the execution of m(Object) instead of
m(String). This occurs because class B no
longer resides in the same package as A. Thus,
m(String) is no longer visible to A, since it
is not a public method. For clarity, a public method of a public class,
like m(Object), can be called from any part of the code.
However, methods without an explicit visibility modifier, like
m(String), can only be called by code within the same
package.
In summary, this Move Class operation cannot be considered a refactoring, because it does not preserve the program’s behavior. If performed with the assistance of an IDE, the IDE should detect this problem and warn the user that the operation cannot be performed as it would alter the program’s behavior.
9.5 Code Smells 🔗
Code Smells—also known as bad smells—are indicators
of low-quality code, that is, code that is difficult to maintain,
understand, modify, or test. In essence, code that does not smell
good
and therefore might need refactoring. However, it’s important
to note that the term indicators
suggests that not every smell
requires an immediate refactoring. This decision depends on various
factors, such as the importance of the code containing the smell and how
often it needs maintenance. With this point clarified, we will present
some examples of code smells in the rest of this section.
9.5.1 Duplicated Code 🔗
Code duplication is a common code smell and one of those with the highest potential to harm the evolution of a system. Duplicated code increases maintenance effort, as changes need to be applied to multiple parts of the code. Consequently, there is a risk of changing one part and overlooking others. Duplicated code also makes the codebase more complex, as data and commands that could be encapsulated in methods or classes are instead scattered throughout the system.
To eliminate code duplication, the following refactorings can be used: Extract Method (recommended when the duplicated code is within two or more methods), Extract Class (recommended when the duplicated code refers to attributes and methods that appear in more than one class), and Pull Up Method (recommended when the duplicated code is a method present in two or more subclasses).
Blocks of duplicated code are called clones. However, different criteria can be used to determine when two code blocks A and B are, in fact, duplicated. These criteria give rise to four types of clones, as described below:
Type 1: when A and B have identical code, differing only in comments and whitespace.
Type 2: when A and B are Type 1 clones, but with potentially different identifiers.
Type 3: when A and B are Type 2 clones, but with minor differences in statements.
Type 4: when A and B are semantically equivalent, but implemented using different algorithms.
Example: To illustrate these types of clones, we will use the following function:
int factorial(int n) {
int fat = 1;
for (i = 1; i <= n; i++)
fat = fat * i;
return fat;
}Next, we present four clones of this function.
Type 1 clone: adds a comment and removes spaces between operators.
int factorial(int n) {
int fat=1;
for (int i=1; i<=n; i++)
fat=fat*i;
return fat; // returns factorial
}Type 2 clone: renames some variables.
int factorial(int n) {
int f = 1;
for (int j = 1; j <= n; j++)
f = f * j;
return f;
}Type 3 clone: adds a statement that prints the value of the factorial.
int factorial(int n) {
int fat = 1;
for (int j = 1; j <= n; j++)
fat = fat * j;
System.out.println(fat); // new statement
return fat;
}Type 4 clone: implements a recursive version of the function.
int factorial(int n) {
if (n == 0)
return 1;
else return n * factorial(n-1);
}In these cases, multiple factorial functions are
unnecessary. One implementation should be chosen and the others
removed.
Real World: In 2013, Aiko Yamashita and Leon Moonen, two researchers from a research lab in Norway, published the results of an exploratory study on code smells involving 85 developers (link). When asked about the smells they were most concerned with, the most common answer was Duplicated Code, with nearly 20 points on the scale used to rank responses. The second most common smell, with half the points, was Long Method, which we will discuss in the following section.
9.5.2 Long Method 🔗
Ideally, methods should be small, with self-explanatory names and a limited number of lines of code. Long Methods are considered a code smell, as they make the code harder to understand and maintain. When we find a long method, we should consider using Extract Method to break it into smaller methods. However, there’s no fixed maximum number of lines that defines a long method, because this depends on the programming language, the method’s relevance, the system’s domain, and other factors. Nevertheless, there is now a tendency to write small methods, with fewer than, for instance, 20 lines of code.
9.5.3 Large Class 🔗
Like methods, classes shouldn’t assume multiple responsibilities or provide services that lack cohesion. Hence, Large Classes are considered a smell because, like long methods, they make the code harder to understand and maintain. Such classes are also more challenging to reuse in another package or system. Large classes are characterized by having many attributes with low cohesion among them. The solution to this smell involves using Extract Class to derive a smaller class B from a larger class A. Afterward, class A gets an attribute of type B.
In-Depth: When a class grows so much that it starts
to monopolize most of the system’s intelligence, it’s called a
God Class or a Blob. Classes with
generic names like Manager, System, or
Subsystem tend to be instances of this smell.
9.5.4 Feature Envy 🔗
This smell corresponds to a method that seems to envy
the data
and methods of another class. In other words, it accesses more
attributes and methods of class B than of its own class A. Therefore, we
may consider using Move Method to migrate it to the envied
class.
The following fireAreaInvalidated2 method is an example
of Feature Envy. It has three method calls, all having the same
abt object of type AbstractTool as their
target. Moreover, it accesses no attributes or calls any methods of its
current class. Therefore, this method should be considered for moving to
AbstractTool.
public class DrawingEditorProxy
extends AbstractBean implements DrawingEditor {
...
void fireAreaInvalidated2(AbstractTool abt , Double r ) {
Point p1 = abt.getView().drawingToView(...);
Point p2 = abt.getView().drawingToView(...);
Rectangle rect = new Rectangle(p1.x, p1.y, p2.x - p1.x, p2.y - p1.y);
abt.fireAreaInvalidated (rect);
}
...
}9.5.5 Long Parameters List 🔗
In addition to being small, methods should, whenever possible, have a limited number of parameters. That is, a Long Parameters List is a smell that can be eliminated in two main ways. First, we should check whether any of the parameters can be obtained directly by the called method, as shown below:
p2 = p1.f();
g(p1, p2);In this case, p2 is unnecessary, as it can be obtained
at the beginning of g:
void g(p1) {
p2 = p1.f(); ...
}Another possibility is to create a class to group related parameters. For example, consider the following method:
void f(Date start, Date end) {
...
}In this scenario, we can create a DateRange class to
represent a range of dates:
class DateRange {
Date start;
Date end;
}
void f(DateRange range) {
...
}9.5.6 Global Variables 🔗
As we studied in Chapter 5, global variables should be avoided, as they result in a poor type of coupling. For this reason, they are considered a code smell. Essentially, global variables make it harder to understand a function without examining other parts of the system. To understand this issue, consider the following function:
void f(...) {
// computes a certain value x
return x + g; // where g is a global variable
}Just from analyzing this code, can the reader tell what
f returns? The answer is no, as we need to know
g’s value. However, since g is a global
variable, its value can be changed anywhere in the program, which can
easily introduce bugs in this function, as a single, distant, and
unrelated line of code can affect f’s result. All it needs
to do is to change the value of g.
It’s also worth noting that in languages like Java, static attributes behave like global variables. Therefore, they also represent a code smell.
9.5.7 Primitive Obsession 🔗
This code smell occurs when primitive types (such as
int, float, String, etc.) are
used instead of specific classes. For example, suppose we need to
declare a variable to store a ZIP code for an address. In a rush, we
might declare it as a String, instead of creating a
dedicated class—such as ZIPCode—for this purpose. The main
advantage of using a dedicated class is that it can provide methods for
manipulating and validating the stored values. For example, the class
constructor can check if the provided ZIP code is valid before
initializing the object. By using a dedicated class, we encapsulate this
responsibility and, consequently, free the clients from this
concern.
In short, we should not be obsessed
with primitive types.
Instead, we should consider creating classes that encapsulate primitive
values and provide operations for handling them. In the next section,
we’ll complement this recommendation by suggesting that such objects,
when possible, should also be immutable.
9.5.8 Mutable Objects 🔗
In the second edition of his book on refactoring, Fowler defines
mutable objects as a code smell. A mutable object is one whose state can
be modified after creation. An immutable object, by contrast, once
created, cannot be changed. To facilitate the creation of immutable
objects, classes should declare all their attributes as private and
final (a final attribute is read-only). The class itself should also be
declared final to prevent the creation of subclasses. Consequently, when
we need to modify an immutable object, the only alternative is to create
a new instance with the desired state. For example, String
objects in Java are immutable, as illustrated in the following
example.
class Main {
public static void main(String[] args) {
String s1 = "Hello World";
String s2 = s1.toUpperCase();
System.out.println(s1);
System.out.println(s2);
}
}This program prints Hello World
and then HELLO WORLD
.
This happens because the toUpperCase method does not change
the s1 string, but instead returns a new string with the
uppercase version of the original one.
Whenever possible, we should create immutable objects, as they can be
shared freely and safely with other functions. For example, in Java, you
can pass a string as a parameter to a function f and be
sure that f will not change its content. This would not be
the case if strings were mutable, as it would be possible for
f to change the string. An additional advantage is that
immutable objects are thread-safe, so there is no need to synchronize
thread access to their methods. The reason is simple: the classic
problems of concurrent systems, such as race conditions, occur only when
multiple threads can change the state of an object. If the state is
immutable, such problems disappear by design.
However, we should understand this code smell within the context of
the programming language used in a project. For example, in functional
languages, objects are immutable by definition, meaning this code smell
will never appear. By contrast, in imperative languages, it is common to
have some mutable objects. For this reason, when using these languages,
we should try to minimize the number of such objects, without, however,
expecting to completely eliminate them. As a guideline, we should make
simple and small objects immutable, such as those representing
ZIPCode, Currency, Address,
Date, Time, Phone,
Color, and Email, among others.
To illustrate, here is the implementation of an immutable
Date type:
record Date(int day, int month, int year) {
public Date {
if (day < 1 || day > 31) {
throw new IllegalArgumentException("Invalid day: " + day);
}
if (month < 1 || month > 12) {
throw new IllegalArgumentException("Invalid month: " + month);
}
}
}This implementation uses records, introduced in Java 16, to simplify
the implementation of immutable data types in the language. A record is
a restricted form of a class. For instance, a record has a name
(Date in this case) and a set of fields (day,
month, and year in our example), which are
final by definition. Furthermore, records automatically
provide default methods, such as toString(),
equals(), and hashCode().
9.5.9 Data Classes 🔗
These classes contain only attributes and no methods, or at most, they include getters and setters. However, as is often the case with code smells, we should not consider every Data Class a major concern. Instead, the important thing is to analyze the code and move relevant behavior to these classes. Specifically, whenever it makes sense, we should add methods to these classes implementing operations that are already being performed elsewhere.
9.5.10 Comments 🔗
It may seem strange to see comments included in a list of code smells. For instance, in introductory programming courses, students are usually encouraged to comment on all the code they produce, with the aim of learning the importance of code documentation. In the book Elements of Programming Style, Brian Kernighan—one of the creators of the Unix operating system and the C programming language—and P. J. Plauger offer advice that clarifies the view of comments as smells. They recommend the following:
Don’t comment bad code, rewrite it.
Thus, the idea is that comments should not be used to explain poorly written code. Instead, we should refactor the code to improve readability. Once the code is refactored, the comments may become redundant. An example of this recommendation can be seen in the context of Long Methods, such as:
void f() {
// task1
...
// task2
...
// taskn
...
}If we apply Extract Method to the commented code, we’ll obtain the following improved version:
void task1() { ... }
void task2() { ... }
void taskn() { ... }
void f() {
task1();
task2();
...
taskn();
}After this refactoring, the comments are no longer necessary, as the method names now clearly convey their purpose.
In-Depth: Technical debt is a term coined by Ward Cunningham in 1992 to designate technical problems that can hinder the maintenance and evolution of a system. These problems include, among others, missing tests, architectural issues (for example, systems that are a Big Ball of Mud), numerous code smells, and a complete lack of documentation. Cunningham’s intention was to create a term that could be understood by managers and others lacking knowledge of software engineering principles and practices. Hence, he chose the term debt to emphasize that these issues, if not resolved, will require the payment of interest. This interest usually manifests as inflexible and difficult-to-maintain systems, where bug fixes and adding new features become increasingly time-consuming and risky.
To illustrate the concept, suppose that adding a new feature F1 to a program would require three days. However, if there were no technical debt, F1 could be implemented in just two days. This one-day difference represents the interest charged by the technical debt in our program. One option is to pay off the principal of this debt, that is, to completely remove the technical debt. But that might take, for instance, four days. In other words, if we plan to evolve the program with F1 only, there’s no advantage. However, suppose that over the next few months we will need to implement more features, such as F2, F3, F4, etc. In this scenario, eliminating the principal of the technical debt might be worthwhile.
Bibliography 🔗
Martin Fowler. Refactoring: Improving the Design of Existing Code, Addison-Wesley, 1st edition, 2000.
Martin Fowler. Refactoring: Improving the Design of Existing Code, Addison-Wesley, 2nd edition, 2018.
Danilo Silva, Nikolaos Tsantalis, Marco Tulio Valente. Why We Refactor? Confessions of GitHub Contributors. ACM SIGSOFT International Symposium on Foundations of Software Engineering (FSE), p. 858-870, 2016.
Exercises 🔗
1. Mark the FALSE alternative:
(a) Refactorings improve the design of a software system.
(b) Refactorings make the code of a system easier to understand.
(c) Refactorings facilitate the detection and fixing of future bugs.
(d) Refactorings speed up the implementation of new features.
(e) Refactorings always improve a system’s runtime performance.
2. The following graph displays the number of features implemented in two similar systems (A and B), developed by comparable teams using the same technologies. In which system do you believe refactorings were systematically performed? Justify your answer.

3. Describe the differences between opportunistic and planned refactorings. Which of these types of refactoring do you think is more common? Justify your answer.
4. Provide the names of refactorings A and B that, if executed in sequence, do not change the system’s code. In other words, refactoring B undoes the transformations made by refactoring A.
5. In these examples, extract the lines commented with the word
extract
to a method named g.
class A {
void f() {
int x = 10;
x++;
print x; // extract
}
}class A {
void f() {
int x = 10;
x++; // extract
print x; // extract
}
}class A {
void f() {
int x = 10;
x++; // extract
print x; // extract
int y = x+1;
...
}
}class A {
void f() {
int x = 10;
int y; // extract
y = h()*2; // extract
print y; // extract
int z = y+1;
...
}
}6. The following function calculates the n-th term of the Fibonacci sequence. The first term is 0, the second term is 1, and thereafter, the n-th term is the sum of the preceding two terms.
int fib(int n) {
if (n == 1)
return 0;
if (n == 2)
return 1;
return fib(n-1) + fib(n-2);
}Describe Type 1, 2, 3, and 4 clones for this function. You do not need to implement the clones; but be precise in specifying how each clone differs from the original code.
7. Consider the following class that stores a monetary value in dollars.
class Currency {
...
private double value = 0.0;
void add(Currency m) {
this.value = this.value + m.getValue();
}
...
}(a) Why are the objects of this class mutable?
(b) Reimplement the class to ensure that its objects are immutable.
8. As discussed in Section 9.5, comments used to explain bad
code
constitute a code smell. In these cases, the ideal solution is
to refactor the code and then remove the comments. Below, we show
another category of comments that can be removed. Explain why these
comments are unnecessary.
// Student class
class Student {
// Student's enrollment number
int enrollment;
// Student's date of birth
Date dateOfBirth;
// Student's address
Address address;
// Default constructor of the Student class
Student() {
...
}
...
}9. Use an IDE to perform a simple refactoring on one of your programs. For example, rename a method. What are the advantages of performing refactorings using IDEs?
10. Use a Java IDE to perform the Move Class refactoring discussed in Section 9.4.1. Did the IDE report any errors? If so, describe these errors.