
Software Engineering: A Modern Approach
7 Architecture 🔗
Architecture is about the important stuff. Whatever that is. – Ralph Johnson
This chapter begins with an introduction to the concept of software architecture (Section 7.1). Following that, we explore several architectural patterns, including Layered Architectures and, specifically, Three-layer Architectures (Section 7.2), MVC (Section 7.3), and Microservices (Section 7.4). In discussing microservices, we explore the context that led to the emergence of this architectural pattern and discuss its benefits and challenges. Subsequently, we examine two architectural patterns proposed to ensure scalability and decoupling in distributed systems: Message-Oriented Architectures (Section 7.5) and Publish/Subscribe (Section 7.6). The chapter concludes by examining other architectural patterns (Section 7.7) and providing an example of an architectural anti-pattern (Section 7.8).
7.1 Introduction 🔗
There is more than one definition for software architecture. One of
the most common definitions considers that architecture is concerned
with high-level design.
Thus, the focus shifts from the
organization and interfaces of individual classes to larger units, such
as packages, components, modules, subsystems, layers, or services—the
specific terminology is less important. Generally, these terms refer to
sets of related classes.
Instead of just being larger
, architectural components must be
relevant and related to the core mission of a system. For instance,
consider an information system. Typically, this system includes a module
to persist data using a database. This module is essential in
information systems, as their main goal is to automate and persist
information related to business processes. Now, consider a system that
uses artificial intelligence techniques to diagnose diseases. This
system may also have a persistence module that stores data about the
diseases that are diagnosed. However, this module is not central to the
main purpose of the system. Therefore, it is not a key part of its
architecture.
There is also a second definition of software architecture. As expressed in Ralph Johnson’s quote that opens this chapter, it considers that software architecture refers to the most important design decisions in a system. These decisions are so important that once made, they are difficult to reverse in the future. Hence, this second way of defining architecture is more general than the one presented in the previous paragraph. It considers that architecture is not just a set of modules but a set of decisions. Among these decisions, the definition of the main modules of the system is undoubtedly included. However, other decisions are also considered, such as the choice of programming language and the database used by the system. In fact, once a system is implemented using a certain database, it is very difficult to migrate to another one. For this reason, even today it is common to find critical systems running on non-relational databases and written in COBOL.
Architectural patterns propose a high-level organization for software systems, including their key modules and the relations between them. These relations define, for example, whether module A may (or may not) call the methods of module B. In this chapter, we will explore the following architectural patterns: Layered Architecture (Section 7.2), Model-View-Controller or MVC Architecture (Section 7.3), Microservices (Section 7.4), Message-Oriented Architecture (Section 7.5), and Publish/Subscribe Architecture (Section 7.6). We’ll then briefly present other architectural patterns, such as Pipes and Filters (Section 7.7). Additionally, we will provide an example of an architectural anti-pattern known as the Big Ball of Mud (Section 7.8).
In-Depth: Some authors—like Taylor et al. (link) —make a distinction between patterns and architectural styles. According to them, patterns focus on solutions to specific architectural problems, while architectural styles propose that the modules of a system should be organized in a certain way without necessarily aiming to solve a specific problem. For example, these authors consider MVC an architectural pattern that solves the problem of separating presentation and model in graphical interface systems. On the other hand, they view Pipes and Filters as an architectural style. In this chapter, however, we will not make this distinction. Instead, we will refer to all of them as architectural patterns.
7.1.1 Tanenbaum-Torvalds Debate 🔗
In early 1992, a heated debate over operating system architectures erupted in an Internet discussion forum. Despite the participation of numerous developers and researchers in this discussion, it became known as the Tanenbaum-Torvalds Debate (link, Appendix A, page 102). Tanenbaum (Andrew) is a researcher in the field of operating systems, the author of textbooks in the area, and a professor at Vrije Universiteit in Amsterdam, the Netherlands. At the time, Torvalds (Linus) was a Computer Science student at the University of Helsinki in Finland.
The discussion began when Tanenbaum posted a message in the forum
titled Linux is obsolete.
His main argument was that Linux
follows a monolithic architecture, where all operating
system functions, such as process management, memory management, and
file systems, are implemented in a single executable file running in
supervisor mode. In contrast, Tanenbaum advocated for a
microkernel architecture, where the kernel handles only
the most basic system functions, and the other functions run as
independent processes outside the kernel. Linus responded emphatically,
asserting that Linux was a practical operating system at the time, while
the microkernel-based system Tanenbaum was developing was facing various
problems and bugs. The discussion intensified, with Tanenbaum even
stating that had Torvalds been his student, he would have received a
poor grade for the monolithic Linux architecture. An interesting comment
was also made by Ken Thompson, one of the designers of the first
versions of Unix:
It is in my opinion easier to implement a monolithic kernel. It is also easier for it to turn into a mess in a hurry as it is modified.
Indeed, Thompson’s prediction proved accurate. In 2009, Torvalds made the following declaration during a conference:
We are definitely not the streamlined, small, hyper-efficient kernel that I envisioned 15 years ago. The kernel is huge and bloated… And whenever we add a new feature, it only gets worse.
This comment is available on a Wikipedia page (link) and was the subject of several articles on technology websites at the time. It underscores that architectural decisions are not only important and difficult to reverse, but their negative consequences can also take years to become apparent and start causing problems.
7.2 Layered Architecture 🔗
Layered architecture is one of the most commonly used architectural patterns, dating back to the first large software systems designed in the 1960s and 1970s. In systems that follow this pattern, classes are organized into modules called layers. The layers are arranged hierarchically, resembling a cake. Consequently, a layer can only use services—meaning it can call methods, instantiate objects, extend classes, declare parameters, or throw exceptions—from the layer immediately below it.
Layered architectures are widely used in the implementation of network protocols. For instance, HTTP is an application protocol that uses services from a transport protocol, such as TCP. TCP, in turn, relies on services from a network protocol, such as IP. Finally, the IP layer uses services from a communication protocol, such as Ethernet.
A layered architecture partitions the complexity involved in implementing a system into smaller components, namely the layers. As an additional advantage, it imposes discipline on the dependencies between these layers. As mentioned earlier, layer n can only use services from layer n-1. This hierarchy aids in understanding, maintaining, and evolving a system. For instance, it becomes easier to substitute one layer for another (e.g., transitioning from TCP to UDP). Additionally, it facilitates the reuse of a layer by upper layers. For example, multiple application protocols, such as HTTP, SMTP, and DHCP, can use the same transport layer.
In-Depth: One of the early proposals for a layered architecture was developed by Edsger W. Dijkstra in 1968 for an operating system called THE (link). The layers proposed by Dijkstra were as follows: multiprogramming (layer 0), memory allocation (layer 1), interprocess communication (layer 2), input/output management (layer 3), and user programs (layer 4). Dijkstra concluded his article by emphasizing that the benefits of hierarchical structures become increasingly important as project size grows.
7.2.1 Three-Tier Architecture 🔗
This architectural pattern is common when building enterprise information systems. Until the late 1980s, enterprise applications—such as payroll, inventory control, and accounting systems—were executed on mainframes, which were physically large and expensive computers. These applications were monolithic and accessed through terminals that had no processing capacity and provided only a textual interface. However, with advancements in network and hardware technologies, it became possible to migrate these systems to other platforms. It was at this point that three-tier architectures emerged as an alternative.
The three layers (or tiers) of this architecture are as follows:
User Interface: Also known as the presentation layer, it is responsible for all user interaction, handling the display of data, and processing inputs and interface events such as button clicks and text highlighting. Typically, this layer is implemented as a desktop application. For example, an academic system might provide a graphical interface for instructors to enter grades for their classes. The main element of this interface could be a form with two columns: student name and grade. The code implementing this form resides in the user interface layer.
Business Logic: Also known as the application layer, it implements the system’s business rules. In the academic system example, a business rule could require that grades must be greater than or equal to zero and less than or equal to the maximum value for the exam. When an instructor enters the grades for an exam, the business logic layer is responsible for checking whether this rule is followed. Another business rule might state that after the grades are entered, the students should be notified via email.
Database: This layer stores the data manipulated by the system. For example, in our academic system, after the grades are entered and validated, they are saved in a database.
As shown in the next figure, a three-tier architecture is a distributed architecture. This means that the user interface layer runs on clients’ machines, the business logic layer runs on a server (often called an application server), and the database tier operates on a separate database server.

In three-tier architectures, the business logic layer can have various modules, including a facade to facilitate system access for clients, and a persistence module that isolates the database from the other modules.
Finally, it’s worth mentioning that two-tier architectures are also possible. In this case, the user interface and business logic layers are combined into a single layer, which runs on the client. The second layer is the database. The disadvantage of such architectures is that all processing occurs on the clients, which therefore must have more computational power.
7.3 MVC Architecture 🔗
The MVC (Model-View-Controller) architectural pattern was proposed in the late 1970s and subsequently used in the implementation of Smalltalk-80, one of the earliest object-oriented programming languages. Smalltalk not only incorporated object-oriented concepts but also played a pioneering role in introducing Graphical User Interfaces (GUI) featuring windows, buttons, scroll bars, and the mouse. This occurred during an era when operating systems offered only command-line interfaces, and programs primarily featured textual interfaces. At that time, screens were essentially a matrix of characters, often with 25 lines and 80 columns, for instance.
MVC was the architectural pattern chosen by Smalltalk designers for the implementation of graphical interfaces. Specifically, MVC defines that the classes of a system should be organized into three groups:
View: Classes responsible for implementing the system’s graphical interface, including windows, buttons, menus, scroll bars, etc.
Controller: Classes that handle events generated by input devices, such as the mouse and keyboard. As a result of such events, the Controller can request changes in the state of the Model or the View. For example, in a calculator, when the user clicks on the
+
button, a Controller class captures this event and calls a method of the Model. As another example, when the user clicks on theDark UI
button, a Controller class is responsible for requesting the View to change its colors to darker shades.Model: Classes that store the data manipulated by the application and related to the system’s domain. These classes have no knowledge of or dependency on View and Controller classes. In addition to data, they can contain methods that perform operations on domain objects.
Therefore, in MVC architectures, the graphical interface is formed by View and Controller objects. However, in many systems, there is no clear distinction between these components. According to Fowler (link, page 331), most Smalltalk implementations do not separate these two components. Thus, MVC can be more easily understood as follows:
MVC = (View + Controllers) + Model = Graphical Interface + Model
The following figure shows the dependencies between the classes in an MVC architecture. The figure emphasizes that the graphical interface is composed of the View and Controller. We can also see that the graphical interface depends on the Model. However, the Model does not have dependencies on graphical interface classes. In fact, we can view the graphical interface as an observer of the Model. When the state of the Model changes, the graphical interface must be updated.

Among the advantages of MVC architectures, we can highlight:
MVC encourages the specialization of development work. For example, we can have developers who are experts in implementing user interfaces, now commonly referred to as front-end developers. Conversely, developers responsible for implementing Model classes do not need to be concerned with user interface code.
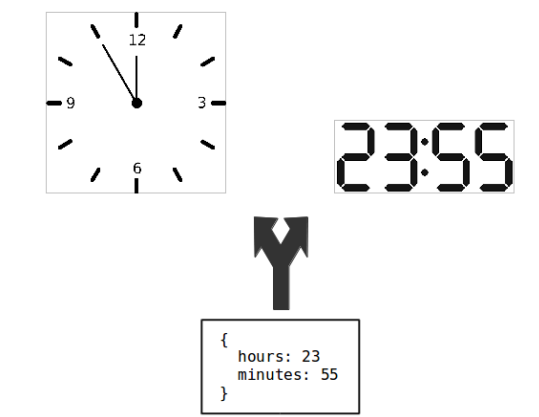
MVC allows Model classes to be used by different Views, as illustrated in the following figure. In this example, a Model object stores two values: hours and minutes. This data is presented in two different Views: an analog clock and a digital clock.
- MVC enhances testability. As we will study in Chapter 8, non-visual objects—that is, those not related to graphical interface implementation—are easier to test. Therefore, by separating View from Model objects, testing the Model becomes easier.
We conclude with a summary of MVC, according to Fowler and Beck (link, Chapter 12, page 370):
The gold at the heart of MVC is the separation between the user interface code (the view, these days often called the presentation) and the domain logic (the model). The presentation classes contain only the logic needed to deal with the user interface. Domain objects contain no visual code but all the business logic. This separates two complicated parts of the program into pieces that are easier to modify. It also allows multiple presentations of the same business logic.
Frequently Asked Questions 🔗
What is the difference between MVC and three-tier architectures? The answer requires some elaboration, and we will base our explanation on the historical evolution of these architectures.
First, as previously mentioned, MVC emerged in the late 1970s to support the construction of graphical user interfaces, i.e., applications that include interfaces with windows, buttons, text boxes, etc. An example is an office suite, with applications such as Word, Excel, and PowerPoint.
In the 1990s, network technologies, distributed systems, and databases became more prevalent, enabling the construction of distributed applications with three tiers. In this context, MVC could be used in the implementation of the presentation layer, which might, for example, be a Windows application. Thus, the application, as a whole, follows a three-tier architecture but uses MVC specifically in the user interface layer.
At the beginning of the 2000s, as the Web became ubiquitous, user interfaces migrated to HTML and, subsequently, to HTML with JavaScript. The confusion between the terms MVC and three-tier architectures arose at this time, primarily due to the emergence of frameworks for implementing web systems that labeled themselves as MVC frameworks. Examples include Spring (for Java), Ruby on Rails, Django (for Python), and Laravel (for PHP). In reality, these frameworks adapt MVC concepts for the Web. For example, they mandate the organization of a web application into three parts (see the following figure): View, composed of HTML pages; Controllers, which process a request and generate a new View as a response; and Model, which is the layer that persists the data in a database management system.

As a result, although web systems are similar to three-tier systems, the most popular web frameworks opted to use typical MVC terms to name their components. Therefore, the best way to answer the question is to state that there are two versions of MVC: the traditional version, which originated with Smalltalk-80, and the Web version, which gained prominence in the early 2000s. This latter version closely resembles three-tier architectures.
7.3.1 Example: Single Page Applications 🔗
In a traditional web application, with forms, menus, and buttons,
every time the user generates an event—such as clicking on a Save
button—an interaction between the browser and the web server occurs.
That is, the browser sends data to the web server, which processes it
and returns a new page. As a result, these applications are less
interactive and responsive due to the frequent delays in communication
between the browser and the web server.
Recently, a new type of web system, called Single Page Applications (SPAs), has emerged. These applications more closely resemble desktop applications than traditional web applications. When loaded, SPAs download all their code into the browser, including HTML pages, CSS files, and JavaScript code. Therefore, even though users are using a browser, they experience an interaction similar to a local application, as the pages do not reload every time they click on a button. Several modern applications are SPAs, including Gmail, for example. Naturally, there is still a server-side component with which the SPA communicates. For instance, when a new email arrives, Gmail updates the list of messages in the inbox. To enable this automatic update, the communication between the SPA and the server is asynchronous.
There are several frameworks—all based on JavaScript—for implementing SPAs. Next, we present a simple code example using Vue.js.
<html>
<script src="https://unpkg.com/vue@2"></script>
<body>
<h3>A Simple SPA</h3>
<div id="ui">
Temperature: {{ temperature }}
<p><button v-on:click="incTemperature">Increment
</button></p>
</div>
<script>
var model = new Vue({
el: '#ui',
data: {
temperature: 60
},
methods: {
incTemperature: function() {
this.temperature++;
}
}
})
</script>
</body>
</html>This application displays a temperature on the browser screen and provides a button to increment it (see figure below).

Interestingly, SPAs follow an architecture similar to the MVC
pattern. In the previous example, the SPA interface, including the View
and Controller, is implemented in HTML, specifically in the code
delimited by the <div> tag. The Model is implemented
in JavaScript, using Vue.js, and is defined within the
<script> tag.
A second interesting point is that Vue.js is responsible for
propagating changes in the Model to the View. For example, when the
incTemperature method is executed, the temperature value is
automatically updated in the interface. The reverse process can also
occur, although it is not exercised in our example. This feature of SPA
frameworks is called two-way data binding.
7.4 Microservices 🔗
As we discussed in Chapter 2, agile methods advocate for rapid iterations with frequent releases to obtain feedback and, if necessary, make changes to a software product. However, even when an organization adopts an agile method—such as Scrum—it may still face challenges when releasing new versions of the software.
This challenge occurs because systems typically follow a monolithic architecture during execution. This means that even if the development is decomposed into modules M1, M2, M3, …, Mn, at runtime, these modules are executed by the operating system as a single process. Consequently, all modules share the same address space. In other words, during runtime, the system becomes a large monolith, as illustrated in the following figure.

In a monolith, there’s always a risk that a change made by a team in one module may introduce a bug in another module. For example, modules Mi and Mj may share a global variable or a static attribute. Thus, a change to this variable, made in Mi, may compromise the behavior of Mj.
To prevent customers from encountering unexpected bugs in their systems, organizations using monolithic architectures often adopt a strict and bureaucratic process for releasing new versions. This process may include manual testing before the system is deployed to production. Manual testing involves a tester executing the system’s most relevant functionalities to simulate a usage session for an end user.
To address this problem—where development has become agile but the release process remains bureaucratic—organizations have begun to migrate their monoliths to an architecture based on microservices. The idea is simple: groups of modules now run as separate processes, without sharing memory. In other words, the system is decomposed into modules not just during development but also at runtime. Consequently, the likelihood of changes in one module causing bugs in other modules is reduced.
When modules are separated into distinct processes, they cannot access internal resources of another module, such as global variables, static attributes, or internal interfaces. Instead, by design, all communication must occur through the public interfaces of the modules. Essentially, microservices are used to ensure that development teams only use the public interfaces of the systems they depend on. Compliance with this rule is enforced by the operating system.
The following figure shows a microservices-based implementation of our initial example. In this new architecture, we still have nine modules. However, they are run by six separate processes, represented by the squares and rectangles surrounding the modules. Modules M1, M2, M3, and M6 are each executed in an independent process. Modules M4 and M5 are executed in a fifth process. Lastly, modules M7, M8, and M9 are executed in a sixth process.

Up to this point, we’ve used the term process, but the architectural pattern name refers to these units as services. These services are considered micro because they do not implement complex features. Remember that they are implemented and maintained by agile teams, which, as we mentioned in Chapter 2, are small. Consequently, small teams don’t have the capacity to implement large services with multiple features.
A second advantage of microservices is scalability.
When a monolith faces performance issues, one solution is to replicate
the system on different machines, as shown in the next figure. This
solution is called horizontal scalability. For example,
it allows us to distribute users across the two instances presented in
the figure. Since they are instances of the same monolith,
they contain exactly the same modules.

However, performance issues may sometimes be caused by specific services; for example, the authentication service. Thus, microservices architectures allow the replication of specific components responsible for performance issues. The next figure shows a new deployment of our microservices-based system.

In this figure, Server 2 contains only instances of M1. This configuration assumes that M1 is responsible for most of the performance problems in the original deployment. Initially, we had a single instance of M1. In this new configuration, we have six instances, all running on Server 2.
We have discussed two advantages of microservices: (1) they allow a system to evolve faster and independently, enabling each team to adopt its own release schedule; and (2) they support scalability at a finer granularity level than is possible with monoliths. However, there are at least two additional advantages:
Since microservices are autonomous and independent, they can be implemented using different technologies, including various programming languages, frameworks, and databases. In an e-commerce system, for example, the customer registration microservice might be implemented in Java with a relational database, while the microservice that provides purchase recommendations could be implemented in Python with a NoSQL database.
When using a monolith, failures are often total. If the database crashes, all services go down. In contrast, microservices-based architectures can experience partial failures. For example, if the recommendation microservice in our e-commerce system becomes unavailable, customers will still be able to search for products, make purchases, etc. However, they will see a message in the recommendation area of the page saying that recommendations are not available at the moment.
Microservice-based architectures have become popular due to the emergence of cloud computing platforms. With these platforms, organizations no longer need to purchase and maintain hardware and basic software, such as operating systems, databases, and web servers. Instead, they can rent virtual machines on a cloud platform and pay by the hour of machine usage. This approach facilitates horizontal scaling of microservices by adding new virtual machines.
In-Depth: Microservices are an example of the application of Conway’s Law. Formulated in 1968 by Melvin Conway, it is one of the empirical laws in software engineering, similar to Brooks’ Law, which we studied in Chapter 1. Conway’s Law suggests that companies tend to adopt software architectures that mirror their organizational structures. In other words, a company’s software architecture tends to reflect its organizational chart. This explains why microservices are primarily used by large Internet companies with hundreds of small development teams distributed across various countries. These companies not only have decentralized structures, but their teams are also autonomous and are continuously encouraged to produce innovations.
7.4.1 Data Management 🔗
Ideally, microservices should be autonomous not only in functionality but also in terms of data. This means they should manage the data associated with their own service. Therefore, the scenario illustrated in the following figure—with two microservices sharing the same database—is not recommended in a microservices-based architecture.

Optimally, M1 and M2 should be independent even in terms of their databases, as shown in the next figure. This separation is important because a single centralized database can easily become a bottleneck for the system’s evolution.

For example, traditional development teams and architectures often share a database administrator, who is responsible for managing the database model. Any change to the database—such as creating a new column in a table—requires approval from this administrator. Therefore, this central authority must manage the conflicting interests of the different teams. Consequently, decision-making may become slow and bureaucratic, impeding the system’s evolution.
7.4.2 When Not to Use Microservices? 🔗
While we’ve presented the advantages of microservices thus far, it’s important to note that this architecture is more complex than a monolithic one. This complexity arises because microservices are independent processes, resulting in a distributed system. Thus, when using microservices, we face several challenges that are typical of such systems, including:
- Complexity: When two modules run in the same process, communication between them occurs through method calls. However, when they are on different machines, the communication must use a network protocol, such as HTTP. For this reason, developers who work with microservices need to master and use a set of technologies for network-based communication.
- Latency: Network-based communication between microservices introduces delay, which we call latency. When a client calls a method in a monolithic system, the latency is minimal. For example, it is rare for a developer to avoid calling a method to improve the performance of their code. However, this scenario changes when the method is on another machine, possibly on the other side of the planet in a global company. In these situations, there is a non-negligible communication cost. Regardless of the communication protocol used, the call must pass through the network cable—or through the air and optical fiber—until it reaches the destination machine.
- Distributed Transactions: As we’ve seen, microservices should be autonomous in terms of data management. However, this autonomy makes it more complex to ensure that operations performed on two or more databases are atomic, meaning either they execute successfully in all databases or they fail entirely. For example, consider two credit card payment microservices, which we’ll call X and Y. Suppose an e-commerce site allows the purchase value to be split between these cards. A $500.00 purchase may be paid by debiting $300.00 on card X and $200.00 on card Y. However, these transactions should be atomic: either both cards are debited or neither is. Therefore, in microservices-based architectures, distributed transaction protocols, like two-phase commit, may be necessary to ensure transaction semantics in operations that write to more than one database.
7.5 Message-Oriented Architectures 🔗
In this type of architecture, communication between clients and servers is mediated by a third-party service that implements a message queue, as the next figure shows.

Clients act as message producers; that is, they insert messages into the queue. Servers act as message consumers; that is, they retrieve messages from the queue and process the information contained in them. A message is a record (or an object) containing a set of values. The message queue is a FIFO-type structure (First In, First Out), meaning that the first message to enter the queue is the first to be processed by the server.
By using message queues, communication becomes asynchronous, as once the information is placed in the queue, the client is free to continue its processing. Therefore, the messaging service must run on a stable machine with high processing power. It is also important for the message queue to be persistent. If the queue goes down, the data must not be lost. Because message queues are widely used in the implementation of distributed systems, there are many ready-made solutions available on the market. This means you probably won’t implement your own message queue but will instead reuse solutions from well-known companies or those maintained by open source communities. Message queues are often referred to as message brokers.
In addition to enabling asynchronous communication between clients and servers, message queues enable two forms of decoupling among the components of a distributed application:
Space decoupling: Clients do not need to know the servers, and vice versa. In other words, the client is an information producer but does not need to know who will consume this information. The same reasoning applies to servers.
Time decoupling: Clients and servers do not need to be simultaneously available to communicate. If the server is down, clients can continue producing messages and placing them in the queue. When the server comes back online, it will process these messages.
Space decoupling makes solutions based on message queues quite flexible. Development teams—both for the client and the server—can work and evolve their systems autonomously. Delays from one team do not affect the work of other teams, for instance. This flexibility is achieved as long as the message format remains stable over time. Meanwhile, time decoupling makes the architecture robust against failures. For example, server failures do not impact clients. However, it is essential that the message broker be stable and capable of storing a large number of messages, as mentioned earlier. To ensure the availability of these brokers, they are usually managed by specialized infrastructure teams.
Message queues also facilitate the scaling of a distributed system. To achieve this, you simply need to configure multiple servers to consume messages from the same queue, as the next figure shows.

7.5.1 Example: Telecommunication Company 🔗
Suppose a telecommunication company has two main systems: Customer and Engineering. The Customer system is responsible for interacting with the company’s customers, for example, to sell Internet packages. In contrast, the Engineering system is responsible for activating and configuring the services that have been sold. This involves configuring the company’s hardware, such as routers and switches. Therefore, when a new customer purchases a service, it must be provisioned in the Engineering system.
This company may use a message queue to mediate the communication between the two systems. Upon selling a new package of services, the Customer system places a message in the queue containing the package information. It is then the responsibility of the Engineering system to process this message and activate the new customer’s service.
When opting for a message queue architecture, the communication between the systems does not occur in real time. For example, if the Engineering system is busy with several complex service activations, it may take some time until a certain service is activated. However, a message queue solution allows services to be activated more quickly than a batch solution. In the latter case, the Customer system generates a file with the services sold each day. This file is processed during the night by the Engineering system. Therefore, a customer might have to wait up to 24 hours to have their service activated.
7.6 Publish/Subscribe Architecture 🔗
In publish/subscribe architectures, messages are referred to as events. The components of the architecture are known as publishers and subscribers. Publishers produce events and publish them to the publish/subscribe service, which is usually run on a separate machine. Subscribers register to receive events that interest them. When an event is published, its subscribers are notified, as shown in the following figure.

Like message queues, publish/subscribe architectures also provide space and time decoupling. However, there are two major differences between publish/subscribe and message queues:
In publish/subscribe, an event generates notifications for all subscribers. In contrast, in message queues, the messages are consumed, i.e., removed from the queue, by one server. Therefore, in publish/subscribe, we have a style of communication from 1 to n, also known as group communication. In message queues, the communication is 1 to 1, also called point-to-point communication.
In publish/subscribe, subscribers are asynchronously notified. First, they subscribe to certain events and then continue their processing. When the events of interest occur, they are notified through the execution of a specific method. Conversely, when using a message queue, the servers must retrieve the messages from the queue.
In publish/subscribe systems, events are organized into topics, which function as event categories. When a publisher produces an event, it must specify the topic. Subscribers can then register for events of a particular topic or set of topics.
Publish/subscribe architectures are sometimes referred to as event-oriented architectures. The publish/subscribe service is also sometimes called an event broker. Notably, these architectures share similarities with the Observer design pattern, as discussed in Chapter 6. However, publish/subscribe is an architectural solution for implementing distributed systems. In this context, publishers and subscribers are different processes and typically located on distinct machines. In contrast, the Observer design pattern is not intended for use in distributed architectures.
7.6.1 Example: Airline Company 🔗
Let’s illustrate a publish/subscribe architecture using an airline’s system as an example. This company has a sales system used by customers to purchase airline tickets. After completing a sale, the system generates an event containing all transaction data, including the date, time, flight number, and passenger name. The following figure illustrates the proposed architecture for the system.

Three systems of the airline subscribe to the sale
event: (1)
the mileage system, which credits the miles related to the ticket into
the passenger’s account; (2) the marketing system, which uses the sale
data to make offers to customers, such as car rentals or upgrades to
business class; and (3) the accounting system, which includes the sale
in the company’s books.
This architecture has the following key characteristics: (1) group communication because the same event is subscribed to by three systems; (2) space decoupling because the sales system does not know which systems are interested in the events it publishes; (3) time decoupling because the publish/subscribe system resends the events if the subscribing systems are down; and (4) asynchronous notification because the subscribers do not need to periodically query the publish/subscribe system about the events of interest.
7.7 Other Architectural Patterns 🔗
Pipes and Filters is a data-oriented architectural pattern in which programs—called filters—process data received as input and generate new output. Filters are connected through pipes, which act as buffers, storing the output data until it is consumed by the next filter in the sequence. Thus, filters don’t know their predecessors or successors, making this architecture flexible and allowing various combinations of programs. Additionally, filters can be executed in parallel. A classic example of a pipe-and-filter-based architecture is the Unix command-line interface. For instance:
ls | grep csv | sort
This command runs three other commands (filters) that are connected by two pipes (vertical bars). In Unix systems, inputs and outputs are text files.
Client/Server is a very common architecture for implementing network services. Clients and servers are the only components in this architecture, and they communicate through a network. Clients request services from servers and wait for responses. Client/Server architectures are used to implement services such as: (1) print service, which enables clients to print to a remote printer that is not physically connected to their machine; (2) file service, which enables clients to access the file system (i.e., the disk) of a server machine; (3) database service, which allows clients to access a database located on another machine; (4) Web service, which allows clients (typically browsers) to access resources (such as HTML pages) provided by a web server.
Peer-to-peer architectures are distributed architectures in which each component can play both the client and the server role. These components—called peers—are both consumers and service providers. For example, BitTorrent is a peer-to-peer protocol for sharing files on the Internet. Applications that implement this protocol can both provide files to the network and download files from other peers.
7.8 Architectural Anti-Patterns 🔗
Let’s conclude this chapter with a description of an architectural
anti-pattern, that is, an architectural organization
that is not recommended. Perhaps the most well-known anti-pattern is
called Big Ball of Mud. This anti-pattern, defined by
Brian Foote and Joseph Yoder, describes systems in which any module can
communicate with any other module, as the following figure illustrates.
Thus, a Big Ball of Mud does not have a defined architecture. Instead,
there is an explosion in the number of dependencies, which results in
spaghetti code.
Consequently, maintenance and evolution become
extremely difficult and risky.

Real World: In an article published in 2009 (link), Santonu Sarkar and
five colleagues—at the time consultants at the Indian company
InfoSys—describe their experience modularizing a large banking system.
The system, implemented in the late 1990s, had since grown tenfold: from
2.5 million to more than 25 million lines of code. According to the
authors, the development teams comprised several hundred engineers.
Although the authors did not use the term, the article characterizes the
architecture of this banking system as a Big Ball of Mud. For example,
the authors mention that a single sources
directory contained
almost 15 thousand files. The authors then analyze the problems of
maintaining this system: (1) the learning time for new engineers had
been steadily increasing, going from three to seven months over a
five-year span; (2) frequently, bug fixes introduced new bugs into the
code; and (3) the time to implement new features, even simple ones, had
also increased considerably.
It might seem that systems like the one described in this article are exceptions. However, they are more common than we might imagine. The root of the problem lies in the gradual transformation of the code base into a Big Ball of Mud. Interestingly, the bank tried to work around this problem by adopting practices such as detailed documentation, code reviews, and pair programming. However, these measures were incapable of fixing the problems caused by the Big Ball of Mud architecture.
Bibliography 🔗
James Lewis, Martin Fowler. Microservices: A definition of this new architectural term. Blog post, 2014.
Martin Fowler. Patterns of Enterprise Application Architecture, Addison-Wesley, 2002.
Martin Fowler. Who Needs an Architect?, IEEE Software, vol. 20, issue 5, p. 11-13, 2003.
Patrick Eugster et al. The Many Faces of Publish/Subscribe. ACM Computing Surveys, vol. 35, issue 2, p. 114-131, 2003.
Glenn Krasner, Stephen Pope. A Cookbook for Using the Model-View Controller User Interface Paradigm in Smalltalk-80. Journal of Object-Oriented Programming, vol. 1, issue 3, p. 26-49, 1988.
Kevlin Henney, Frank Buschmann, Douglas Schmidt. Pattern-Oriented Software Architecture: A Pattern Language for Distributed Computing, vol. 4, John Wiley & Sons, 2007.
Exercises 🔗
1. Given their complexity, database systems are relevant components in the architecture of many modern systems. True or false? Justify your answer.
2. Describe three advantages of using MVC (Model-View-Controller) architectures.
3. Compare and contrast the role of Controller classes in a traditional MVC architecture with their role in a web system implemented using an MVC framework such as Ruby on Rails.
4. Describe four advantages of adopting a microservices architecture.
5. Why aren’t microservices a silver bullet? Describe at least three challenges or disadvantages of implementing such an architecture.
6. Analyze the relationship between Conway’s Law and the adoption of a microservices architecture.
7. Define space and time decoupling in the context of distributed systems. How do message queues and publish/subscribe architectures facilitate these forms of decoupling?
8. In which scenarios should an organization consider implementing message queues or a publish/subscribe architecture? Provide specific examples to support your answer.
9. Define the concept of topics in a publish/subscribe architecture and explain how they facilitate message distribution.