
Software Engineering: A Modern Approach
5 Design Principles 🔗
The most fundamental problem in computer science is problem decomposition: how to take a complex problem and divide it up into pieces that can be solved independently. – John Ousterhout
This chapter begins with an introduction to software design, defining and emphasizing the importance of this activity (Section 5.1). We then discuss relevant properties of software design, covering Conceptual Integrity (Section 5.2), Information Hiding (Section 5.3), Cohesion (Section 5.4), and Coupling (Section 5.5). In Section 5.6, we discuss a set of design principles, including Single Responsibility, Interface Segregation, Dependency Inversion, Prefer Composition over Inheritance, Law of Demeter, Open-Closed, and Liskov Substitution. Lastly, we explore the use of metrics to evaluate the quality of software designs (Section 5.7).
5.1 Introduction 🔗
John Ousterhout’s statement that opens this chapter provides an excellent definition of software design. Although not explicitly stated, it assumes that when we talk about design, we are indeed seeking a solution to a particular problem. In Software Engineering, this problem consists of implementing a system that meets the functional and non-functional requirements defined by the customers—or Product Owner/Manager, to use modern terms. Subsequently, Ousterhout suggests how we should proceed to devise this solution: we must decompose, i.e., break down the initial problem, which may be quite complex, into smaller parts. The statement then imposes a restriction on this decomposition: it must allow each part of the project to be solved or implemented independently.
This definition may create the impression that design is a simple activity. However, when designing software, we have to contend with a significant adversary: the complexity of modern software systems. For this reason, Ousterhout emphasizes that problem decomposition is a fundamental challenge not only in software engineering but also in computer science.
The key strategy for overcoming the inherent complexity in software design is to create abstractions. In software engineering, an abstraction is a simplified representation of a given entity. Despite this simplification, we can interact with and take advantage of the abstracted entity without having to know the details of its implementation. Functions, classes, interfaces, and packages are classic abstractions provided by programming languages.
In summary, the primary objective of software design is to decompose a problem into smaller parts. These parts should be implementable independently and, equally importantly, manageable at a higher level of abstraction. Although implementing them might be challenging for the developers directly involved, the created abstractions should be simple for other developers to use.
5.1.1 Example 🔗
To illustrate this discussion of software design, we will use the example of a compiler. The requirements in this case are clear: given a program in a language X, it should be converted into a program in a language Y, which is usually the machine’s language. However, designing a compiler is not trivial. After years of research, a solution (or design) for implementing compilers was proposed, as illustrated in the following figure.

Our initial problem, i.e., designing a compiler, was broken down into
four smaller problems, which we will briefly describe next. First, we
need to implement a lexical analyzer, which breaks down the input file
into tokens (like if, for, while,
x, +, etc.).
Next, we need to implement a syntax analyzer, which analyzes the tokens to check if they follow the source language grammar. After that, we transform the list of tokens into a hierarchical structure, known as an Abstract Syntax Tree (AST). Finally, we implement the semantic analyzer, which is used to detect, for example, type errors; and the code generator, which converts the program’s AST into a lower-level language that can be executed by a given hardware or virtual machine.
This description, although simple, clearly illustrates the objective of software design: to decompose a problem into smaller parts. In our example, we have to design and implement a lexical analyzer, a syntax analyzer, a semantic analyzer, and a code generator. While there are many challenges in each of these tasks, we are closer to a solution than when we started to think about the compiler design.
Continuing with the example, implementing the lexical analyzer may require some effort. However, it should be as simple to use as invoking a function that returns the next token from the input file:
String token = Scanner.next_token();
In this way, we have managed to encapsulate (or abstract) the complexity of a lexical analyzer into a single function.
5.1.2 Topics of Study 🔗
Software design depends on experience and, to some extent, talent and creativity. Despite this, high-quality designs often share some properties. Thus, we will begin by covering design properties, such as conceptual integrity, information hiding, cohesion, and coupling. Afterward, we will shift our focus to design principles, which are guidelines for ensuring that a design meets the aforementioned properties. A quantitative approach, based on metrics, can also be used to evaluate design properties. Thus, to conclude the chapter, we will study metrics for assessing cohesion, coupling, and complexity.
Note: The properties and principles discussed in this chapter apply to object-oriented design. That is, we assume we are dealing with systems implemented (or that will be implemented) in programming languages such as Java, C++, C#, Python, Go, Ruby, and TypeScript. While some of the covered topics apply to structured designs (using languages such as C) or to functional designs (using languages such as Haskell, Elixir, Erlang, and Clojure), it’s not our goal to provide complete coverage of the design aspects in such cases.
5.2 Conceptual Integrity 🔗
Conceptual integrity is a design property proposed by Frederick Brooks—the same professor behind Brooks’ Law, as we mentioned in Chapter 1. Brooks articulated this property in 1975 in the first edition of his book, The Mythical Man-Month (link). Brooks argues that software should not be a mere collection of features lacking coherence and cohesion. Instead, conceptual integrity facilitates system usage and comprehension. When we follow this property, a user familiar with one part of a system feels comfortable using another part, as the features and user interface remain consistent.
To provide a counterexample, let’s consider a system that uses tables to present its results. However, depending on the page, these tables have different layouts in terms of font sizes, the use of bold, line spacing, and so on. In some tables, users can sort the data by clicking on the column titles, but in others, this feature is not available. Moreover, the values representing prices are shown in different currencies: in some tables, they are in euros; in others, they are in dollars. These issues denote a lack of conceptual integrity and, as a result, add accidental complexity to the system’s use and understanding.
In the first edition of his book, Brooks emphatically defended the principle, stating on page 42:
Conceptual integrity is the most important consideration in system design. It is better to have a system omit certain anomalous features and improvements, but to reflect one set of design ideas, than to have one that contains many good but independent and uncoordinated ideas.
Twenty years later, in a commemorative edition marking the 20th anniversary of the book (link, page 257), Brooks reaffirmed the principle with even greater conviction:
Today I am more convinced than ever. Conceptual integrity is central to product quality.
Every time we discuss conceptual integrity, a debate arises about
whether the principle requires a central authority, such as a single
architect or product manager, to decide which functionalities will be
included in the system. On the one hand, this role is not part of the
definition of conceptual integrity. On the other hand, there is a
consensus that key design decisions should not be delegated to large
committees. When this happens, the tendency is to produce systems with
more features than necessary, leading to bloated systems. For example,
one group may advocate for feature A, while another advocates feature B.
These features might be mutually exclusive, but to reach a consensus,
the committee might decide to implement both. As a result, both groups
are satisfied, despite the system’s conceptual integrity being
compromised. A phrase that nicely illustrates this discussion is: A
camel is a horse designed by a committee.
The previous paragraphs emphasized the impact of a lack of conceptual integrity on customers. However, this property also applies to the design and source code of software systems. In this case, the affected parties are the developers, who may face increased challenges in comprehending, maintaining, and evolving the system. Here are some examples of how a lack of conceptual integrity can manifest at the code level:
Inconsistent naming conventions for variables across the system (e.g., camel case, like
totalScore, in one part; and snake case, liketotal_score, in another).Use of different versions of a Web framework in different parts of the system.
Similar problems solved using different data structures across different parts of the system.
Inconsistent methods for retrieving necessary information throughout the system (e.g., retrieving a server address from a configuration file in some functions and as a parameter in others).
These examples reveal a lack of standardization and, consequently, a lack of conceptual integrity. This inconsistency creates difficulties for developers responsible for maintaining one part of the system when they are later assigned to maintain another part.
Real World: Santiago Rosso and Daniel Jackson, researchers from MIT in the USA, provide an example of a system that implements two similar functionalities, which is a potential indicator of conceptual integrity issues (link). They highlight a well-known blogging system where, if a user included a question mark in the title of a post, a window would open, asking if they wanted to allow answers to that post. However, this approach led to user confusion, as the system already had a commenting feature. The confusion arose from the presence of two similar functionalities: comments (for regular posts) and answers (for posts with titles ending in a question mark).
5.3 Information Hiding 🔗
This property was first discussed in 1972 by David Parnas, in one of the most influential software engineering papers of all time, entitled On the Criteria to Be Used in Decomposing Systems into Modules (link). The paper’s abstract begins as follows:
This paper discusses modularization as a mechanism for improving the flexibility and comprehensibility of a system while allowing the shortening of its development time. The effectiveness of a “modularization” is dependent upon the criteria used in dividing the system into modules.
Parnas uses the term module in his paper, written at a time when object orientation had not yet emerged, at least not as we know it today. In this chapter, written almost 50 years after Parnas’ work, we use the term class instead of module. The reason is that classes are the principal units of modularization in popular programming languages, such as Java, C++, and TypeScript. However, the concepts in this chapter also apply to other modularization units, including those smaller than classes, such as methods and functions, as well as larger ones, like packages.
Note: Some authors prefer the term Encapsulation instead of Information Hiding. Indeed, these concepts are synonymous. This equivalence is illustrated in Bertrand Meyer’s Object-Oriented Software Construction, which includes a glossary of software design terms where the entry for Encapsulation simply directs the reader to Information Hiding.
Information hiding offers the following advantages to a software project:
Parallel development: Suppose a system is implemented using classes C1, C2, …, Cn. If these classes hide their internal design decisions, it becomes easier to assign their implementation to different developers. This ultimately leads to a reduction in the time required to implement the system.
Changeability: Suppose we discover that class Cx has performance problems. If the implementation details of Cx are hidden from the rest of the system, it becomes easier to replace it with another class Cy, which uses a more efficient data structure and algorithm. This change is also less likely to result in bugs in other classes.
Comprehensibility: Suppose new developers are hired by the company. They can then be assigned to work on specific classes only. In other words, they will not need to comprehend the entire system, but only the implementation of the classes for which they are responsible.
To achieve these benefits, classes must hide their design decisions
that are subject to change. A design decision is any aspect of the
class’s design, such as the algorithms and data structures used in its
code. Nowadays, the attributes and methods that a class intends to hide
are declared with the private modifier, available in
languages such as Java, C++, C#, and Ruby.
However, information hiding does not mean that a class should
encapsulate all its data and code. Doing so would result in a class
lacking usefulness. Indeed, a useful class must have public
methods that can be called by clients. We also say that a class’s public
members define its interface. This concept is very
important, as it represents the visible part of the class.
Interfaces must be stable, as changes in a class’s interface may
trigger updates in clients. For example, consider a class
Math, with methods providing mathematical operations. Let’s
say it has a method sqrt that computes the square root of
its parameter. If this method’s signature were changed to throw an
exception when the argument is negative, this modification would affect
the clients that call sqrt, as they would have to make
their calls in a try block and be prepared to
catch the exception.
5.3.1 Example 🔗
Consider a system for managing parking lots. The main class of this system is as follows:
import java.util.Hashtable;
public class ParkingLot {
public Hashtable<String, String> vehicles;
public ParkingLot() {
vehicles = new Hashtable<String, String>();
}
public static void main(String[] args) {
ParkingLot p = new ParkingLot();
p.vehicles.put("TCP-7030", "Accord");
p.vehicles.put("BNF-4501", "Corolla");
p.vehicles.put("JKL-3481", "Golf");
}
}This class does not hide its internal data that might change in the
future. Specifically, the hash table that stores the vehicles in the
parking lot is public. Thus, clients, such as the main
method, have access to this data and can, for example, add vehicles to
the ParkingLot. If we decide to use another data structure
in the future, we will need to update all client code.
This first implementation of ParkingLot is equivalent to
a manual parking system where customers, after parking their car, enter
the control booth and write down their car’s license plate and model on
a log sheet.
Next, we show an improved implementation, where the class
encapsulates the data structure responsible for storing the vehicles. To
park a vehicle, there is now a park method. This gives the
class developers the freedom to change the internal data structures
without impacting the client code. The only restriction is that the
signature of the park method should be preserved.
import java.util.Hashtable;
public class ParkingLot {
private Hashtable<String, String> vehicles;
public ParkingLot() {
vehicles = new Hashtable<String, String>();
}
public void park(String license, String vehicle) {
vehicles.put(license, vehicle);
}
public static void main(String[] args) {
ParkingLot p = new ParkingLot();
p.park("TCP-7030", "Accord");
p.park("BNF-4501", "Corolla");
p.park("JKL-3481", "Golf");
}
}In summary, this new version hides a data structure that is subject
to future changes. It also provides a stable interface for use by the
clients of the class, as represented by the park
method.
Real World: In 2002, it is reported that Amazon’s CEO, Jeff Bezos, sent an email to the company’s developers with the following software design guidelines (this message is also mentioned in the software engineering textbook by Fox and Patterson (link, page 81)):
1. All teams responsible for different subsystems of Amazon.com
will henceforth expose their subsystem’s data and functionality through
service interfaces only.
2. No subsystem is to be allowed direct access to the data owned
by another subsystem; the only access will be through an interface that
exposes specific operations on the data.
3. Furthermore, every interface must be designed so that someday
it can be exposed to outside developers, not just used within
Amazon.com.
These guidelines effectively mandated that Amazon developers adhere to the information-hiding principles proposed by Parnas in 1972.
5.3.2 Getters and Setters 🔗
Methods get and set, often referred to
simply as getters and setters, are widely used in object-oriented
languages. A common recommendation for using these methods is as
follows: all data in a class should be private; if external access is
required, it should be done via getters (for read access) and setters
(for write access).
The following Student class is an example, where
get and set methods are used to access an
enrollmentNumber attribute.
class Student {
private int enrollmentNumber;
...
public int getEnrollmentNumber() {
return enrollmentNumber;
}
public void setEnrollmentNumber(int enrollmentNumber) {
this.enrollmentNumber = enrollmentNumber;
}
...
}However, getters and setters do not ensure information hiding. On the contrary, they are a source of information leakage. John Ousterhout offers the following perspective on these methods (link, Section 19.6):
Although it may make sense to use getters and setters if you must expose instance variables, it’s better not to expose instance variables in the first place. Exposed instance variables mean that part of the class’s implementation is visible externally, which violates the idea of information hiding and increases the complexity of the class’s interface.
In essence, carefully consider whether you need to expose a class’s private information. If exposure is truly necessary, implementing it through getters and setters is preferable to making the attribute directly public.
Returning to our Student class example, let’s assume
that it’s important for clients to read and modify students’ enrollment
numbers. In this scenario, providing access through getters and setters
is advantageous for the following reasons:
Future changes, such as retrieving the enrollment number from a database instead of main memory, can be implemented in the
getmethod without impacting client classes.If additional logic becomes necessary, such as adding a check digit to enrollment numbers, it can be implemented in the
setmethod without affecting the clients.
Furthermore, getters and setters are required by some libraries, such as debugging, serialization, and mock libraries (we will study more about mocks in Chapter 8).
5.4 Cohesion 🔗
A class’s implementation should be cohesive, meaning that each class should fulfill a single function or service. Specifically, all methods and attributes of a class should contribute to the implementation of the same service. Another way to explain cohesion is to state that every class should have a single responsibility in the system. In other words, there should be only one reason to modify a class.
Cohesion offers the following advantages:
It simplifies the implementation, understanding, and maintenance of a class.
It makes it easier to assign a single developer to maintain a class.
It facilitates reuse and testing, as cohesive classes are simpler to reuse and test compared to those handling multiple tasks.
Separation of concerns is another recommended property in software design, closely related to the concept of cohesion. It recommends that a class should implement only one concern. In this context, concern refers to any functionality, requirement, or responsibility of the class. Therefore, the following recommendations are equivalent: (1) a class should have a single responsibility; (2) a class should implement a single concern; (3) a class should be cohesive.
5.4.1 Examples 🔗
Example 1: The previous discussion was about class cohesion. However, the concept also applies to methods or functions. Consider the following example:
float sin_or_cos(double x, int op) {
if (op == 1)
"calculates and returns the sine of x"
else
"calculates and returns the cosine of x"
}This function—which is an extreme example and hopefully uncommon in practice—has a serious cohesion problem, as it does two things: calculating either the sine or cosine of its argument. It is then highly advisable to have separate functions for each of these tasks.
Example 2: Now, consider the following class:
class Stack<T> {
boolean empty() { ... }
T pop() { ... }
void push (T item) { ... }
int size() { ... }
}This is a cohesive class, as all its methods implement essential
operations of the Stack data structure.
Example 3: Let’s return to the
ParkingLot class, to which we’ve added four manager-related
attributes:
class ParkingLot {
...
private String managerName;
private String managerPhone;
private String managerSSN;
private String managerAddress;
...
} However, the primary responsibility of this class is to control
parking lot operations, including methods like park(),
calculatePrice(), and releaseVehicle(), among
other related tasks. Thus, it should not assume responsibilities related
to managing employees. For that purpose, a separate class, such as
Employee, should be created.
5.5 Coupling 🔗
Coupling refers to the strength of the connection between two modules. Although it might sound simple, the concept is subject to some nuances. For clarity, we will divide coupling into two main types: acceptable coupling and poor coupling.
We have a case of acceptable coupling between class A and class B when:
Class A only uses public methods from class B.
The interface provided by B is stable, both syntactically and semantically. This means that the signatures of B’s public methods do not change frequently, and neither does the behavior of these methods. As a result, changes in B will rarely impact A.
In contrast, we have a case of poor coupling between class A and class B when changes in B can easily impact A. This occurs mainly in the following situations:
When classes A and B share global variables or data structures, for instance, when B changes the value of a global variable used by A.
When class A directly accesses a file or database used by class B.
When B’s interface is not stable. For example, when the public methods of B are frequently renamed.
Poor coupling is characterized by dependencies between classes that are not mediated by a stable interface. For example, it is difficult to assess the impact that updating a global variable may have on other parts of the system. Conversely, when an interface is updated, this impact is more explicit. In statically typed languages, for example, the compiler will indicate the code that needs to be modified.
In essence, coupling is not necessarily bad, particularly when it occurs with the interface of a stable class that provides a relevant service to the source class. Poor coupling, however, should be avoided, as it refers to coupling that is not mediated by stable interfaces.
There is a common recommendation regarding coupling and cohesion:
Maximize cohesion and minimize coupling.
Indeed, if a class depends on many other classes, it might be taking
on too many responsibilities in the form of non-cohesive features.
Remember that a class should have a single responsibility (or a single
reason to change). However, we should be careful with the meaning of
minimize coupling
in this case. The objective is not to
completely eliminate coupling, as it is natural for a class to depend on
other classes, especially those that implement basic services, such as
data structures and input/output. Instead, the goal is to eliminate or
minimize poor coupling while maintaining acceptable coupling where
necessary.
5.5.1 Examples 🔗
Example 1: Consider the ParkingLot
class, as used in Section 5.3, which has the Hashtable
attribute. Therefore, ParkingLot is coupled to
Hashtable. However, according to our classification, this
is an acceptable coupling; that is, it should not be a cause for major
concern, for the following reasons:
ParkingLotonly uses the public methods ofHashtable.The
Hashtableinterface is stable, as it is part of Java’s API (assuming the code is implemented in this language). Thus, a change in the public interface ofHashtablewould affect not onlyParkingLotbut potentially millions of other classes in Java projects around the world.
Example 2: Consider the following code, where a file
is shared by classes A and B, maintained by
distinct developers. The B.g() method writes an integer to
the file, which is read by A.f(). This form of
communication results in poor coupling between these classes. For
instance, B’s developer might not be aware that the file is
being used by A. Consequently, to facilitate the
implementation of a new feature, they might change the file format
without notifying the maintainer of A.
class A {
private void f() {
int total; ...
File file = File.open("file1.db");
total = file.readInt();
...
}
}class B {
private void g() {
int total;
// computes total value
File file = File.open("file1.db");
file.writeInt(total);
...
file.close();
}
}It’s worth noting that in this example, there is also coupling
between B and File. However, this is an
acceptable coupling since the class must access a file. In this case,
using a class File from the language API is the most
appropriate approach.
Example 3: The following code shows an improved
implementation for classes A and B from the
previous example:
class A {
private void f(B b) {
int total;
total = b.getTotal();
...
}
}class B {
private int total;
public int getTotal() {
return total;
}
private void g() {
// computes total value
File file = File.open("file1.db");
file.writeInt(total);
...
}
}In this new implementation, the dependency of A on
B is made explicit. First, B has a public
method that returns total. Furthermore, class
A depends on B through a parameter in
f, which is used to call getTotal(). This
method is public, so B’s developers have explicitly decided
to expose this information to clients. As a result, in this new version,
the coupling from A to B is now acceptable and
does not raise major concerns.
Interestingly, in the first implementation (Example 2), class
A doesn’t declare any variable or parameter of type
B. Despite that, there is a poor form of coupling between
the classes. In the second implementation, the opposite occurs, as
A.f() has a parameter of type B. However, the
coupling in this case is of a better nature, as it is easier to study
and maintain A without knowing details about
B.
Some authors also use the terms structural coupling and evolutionary coupling, with the following meanings:
Structural Coupling between A and B occurs when a class A has an explicit reference in its code to a class B. For example, the coupling between
ParkingLotandHashtableis structural.Evolutionary (or Logical) Coupling between A and B occurs when changes in class B usually propagate to class A. Thus, in Example 2, where class A depends on an integer stored in a file maintained by B, there is an evolutionary coupling between A and B. For instance, changes in the file format would have an impact on A.
Structural coupling can be acceptable or poor, depending on the stability of the target class’s interface. Evolutionary coupling, especially when most changes in B propagate to other classes, represents poor coupling.
During his time working at Facebook (now Meta), Kent Beck created a glossary of software design terms. In this glossary, coupling is defined as follows: (link):
Two elements are coupled if changing one implies changing the other. […] Coupling can be subtle (we often see examples of this at Facebook). Site events, where parts of the site stop working for a time, are often caused by nasty bits of coupling that no one expected—changing a configuration in system A causes timeouts in system B, which overloads system C.
The definition of coupling proposed by Beck—two elements are
coupled if changing one implies changing the other
—corresponds to
our definition of evolutionary coupling. It appears that Beck is not
concerned about acceptable coupling (i.e., structural coupling that is
stable). Indeed, he comments on that in the second paragraph of the
glossary entry:
Coupling is expensive but some coupling is inevitable. The responsive designer eliminates coupling triggered by frequent or likely changes and leaves in coupling that doesn’t cause problems in practice.
Beck’s definition also makes it clear that coupling can be indirect. That is, changes in A can propagate to B, and then affect C.
Real World: An example of a real problem caused by
indirect coupling became known as the left-pad episode.
In 2016, a copyright dispute prompted a developer to remove one of his
libraries from the npm directory, widely used for distributing Node.js
software. The removed library implemented a single JavaScript function
named leftPad with only 11 lines of code. It filled a
string with blanks to the left. For example,
leftPad ('foo', 5) would return ' foo', i.e.,
foo
with two blanks to the left.
This trivial function’s removal had far-reaching consequences due to indirect dependencies. Thousands of sites were affected because they used npm to dynamically download library A1, which in turn depended on a library A2, and so on until reaching a library An with a direct dependency on left-pad. As a result, this entire chain of dependencies was disrupted for a few hours until left-pad was reinserted into the npm repository. In short, numerous sites were affected by a problem in a trivial library, and most were unaware they indirectly depend on it.
5.6 SOLID and Other Design Principles 🔗
Design principles are recommendations that software developers should follow to achieve the design properties we presented in the previous section. Thus, the properties can be seen as generic qualities of good designs, while the principles serve as practical guidelines.
We will examine seven design principles, as listed in the following table. The table also shows the properties addressed by each principle.
| Design Principle | Design Property |
|---|---|
| Single Responsibility | Cohesion |
| Interface Segregation | Cohesion |
| Dependency Inversion | Coupling |
| Prefer Composition over Inheritance | Coupling |
| Law of Demeter | Information Hiding |
| Open-Closed | Extensibility |
| Liskov Substitution | Extensibility |
Five of these are known as SOLID Principles, which is an acronym created by Robert Martin and Michael Feathers (link). The name comes from the initial letters of the principles:
- Single Responsibility Principle
- Open Closed Principle
- Liskov Substitution Principle
- Interface Segregation Principle
- Dependency Inversion Principle
The design principles we will discuss share a common goal: they address design problems and ensure that the proposed solution can be more easily maintained and evolved over time. Major challenges in software projects often arise during maintenance. Typically, maintenance tasks, including bug fixes and the implementation of new features, tend to become progressively slower, more costly, and riskier. Thus, the design principles we will study help to produce flexible designs that make maintenance easier.
5.6.1 Single Responsibility Principle 🔗
This principle is an application of the idea of cohesion. It proposes
that every class should have a single responsibility. In this context,
responsibility means reasons for changing a class.
Thus, there
should be only one reason to modify any class in a system.
An important corollary of this principle is the recommendation to separate presentation from business logic. In other words, a system should have presentation classes, which implement the interface with users, and classes responsible for business logic. The latter classes perform computations directly related to the solution domain. These represent distinct concerns and responsibilities, which undergo modifications for different reasons. Consequently, they should be implemented in separate classes. In fact, it is not surprising that there are developers who specialize only in front-end development (i.e., presentation classes) and those who specialize in back-end development (i.e., classes that implement business logic).
Example: The following Course class
illustrates a violation of the Single Responsibility Principle. The
calculateDropoutRate method has two responsibilities:
calculating the dropout rate of a course and presenting it on the system
console.
class Course {
void calculateDropoutRate() {
double rate = ...; // compute dropout rate
System.out.println(rate);
}
}A better design separates these responsibilities in two classes: a
user interface class (Console) and a domain-related class
(Course), as shown in the following code. This solution
offers several benefits, including the reuse of the domain class with
other interface classes, such as web or mobile interfaces.
class Console {
void printDropoutRate(Course course) {
double rate = course.calculateDropoutRate();
System.out.println(rate);
}
}
class Course {
double calculateDropoutRate() {
double rate = "compute the dropout rate";
return rate;
}
}5.6.2 Interface Segregation Principle 🔗
This principle, like the previous principle, is an application of the idea of cohesion. In fact, it can be considered a particular case of Single Responsibility, but with a focus on interfaces. The principle states that interfaces should be small, cohesive, and, more importantly, specific to each type of client. Its aim is to prevent clients from depending on interfaces with many methods they won’t use. To avoid this, two or more specific interfaces can, for example, replace a general-purpose one.
A violation of the principle occurs, for example, when an interface has two sets of methods, Mx and My. The first set is used by clients Cx (which do not use the methods in My). Conversely, methods in My are used only by clients Cy. Consequently, this interface should be split into two smaller and more specific interfaces: one interface containing only the methods in Mx and another containing only the methods in My.
Example: Consider an Account interface
with the following methods: (1) getBalance, (2)
getInterest, and (3) getSalary. This interface
violates the Interface Segregation Principle because only savings
accounts pay interest and only salary accounts have an associated salary
(assuming the latter are used by companies to deposit employees’ monthly
salaries).
interface Account {
double getBalance();
double getInterest(); // only applicable to SavingsAccount
double getSalary(); // only applicable to SalaryAccount
}An alternative that follows the Interface Segregation Principle is to
create two specific interfaces (SavingsAccount and
SalaryAccount) that extend the generic one
(Account).
interface Account {
double getBalance();
}
interface SavingsAccount extends Account {
double getInterest();
}
interface SalaryAccount extends Account {
double getSalary();
} 5.6.3 Dependency Inversion Principle 🔗
This principle advocates that client classes should primarily depend
on abstractions rather than on concrete implementations, as abstractions
(i.e., interfaces) tend to be more stable than concrete implementations
(i.e., classes). The principle aims to invert
the dependencies:
clients should rely on interfaces instead of concrete classes.
Therefore, a more intuitive name for the principle would be
Prefer Interfaces to Classes.
To illustrate the principle, consider an interface I and
a class C1 that implements it. Ideally, a client should
depend on I and not on C1. This decision makes
the client immune to changes in the interface’s implementations. For
example, if another class C2 is used to implement
I, this change will have no impact on the client code.
Example 1: The following code illustrates the
scenario previously described. Here, the Client class can
work with concrete objects from classes C1 and
C2. Importantly, it does not need to know the concrete
class that implements the interface I on which it
depends.
interface I { ... }
class C1 implements I {
...
}
class C2 implements I {
...
}class Client {
private I i;
public Client(I i) {
this.i = i;
...
} ...
}class Main {
void main() {
C1 c1 = new C1();
new Client(c1);
...
C2 c2 = new C2();
new Client(c2);
...
}
}Example 2: This example further illustrates the
Dependency Inversion Principle. In the code below, this principle
justifies the choice of the interface Projector as the type
of the g method parameter, rather than a specific
implementation.
void f() {
EpsonProjector projector = new EpsonProjector();
...
g(projector);
}void g(Projector projector) { // Projector is an interface
...
}In the future, the type of the local variable projector
in f could change to, for instance,
SamsungProjector. If this occurs, the implementation of
g will continue working, because using an interface allows
us to receive parameters of any class that implements it.
Example 3: As a final example, suppose a library
that provides a List interface and three concrete
implementations (classes) for it: ArrayList,
LinkedList, and Vector. Ideally, clients of
this library should declare variables, parameters, and attributes using
the List interface, as this decision makes their code
automatically compatible with the three current implementations of this
interface, as well as any future ones.
5.6.4 Prefer Composition Over Inheritance 🔗
Before explaining the principle, it’s important to distinguish between two types of inheritance:
Class inheritance (example:
class A extends B) involves code reuse. Throughout this book, we will refer to class inheritance simply as inheritance.Interface inheritance (example:
interface I extends J) does not involve code reuse. This form of inheritance is simpler and does not raise major concerns. When necessary, we will refer to it explicitly as interface inheritance.
Regarding the principle, when object-oriented programming gained popularity in the 1980s, inheritance was often viewed as a magical solution to software reuse. Consequently, designers at that time began to consider deep class hierarchies as indicators of robust design. However, over time, it became clear that inheritance was not the magical solution it was once thought to be. Rather, it typically introduces maintenance and evolution problems due to the strong coupling between subclasses and their superclasses. These problems are described, for example, by Gamma and colleagues in their book on design patterns (link, page 19):
Because inheritance exposes a subclass to details of its parent’s implementation, it’s often said that inheritance breaks encapsulation. The implementation of a subclass becomes so bound up with the implementation of its parent class that any change in the parent’s implementation will force the subclass to change.
However, we should note that the principle does not prohibit the use of inheritance. It merely suggests that when faced with two design solutions—one based on inheritance and the other on composition—the latter is generally preferable. To clarify, a composition relationship exists when a class A contains an attribute whose type is another class B.
Example: Suppose we need to implement a
Stack class. There are at least two solutions: via
inheritance or composition, as shown next:
Implementation using inheritance:
class Stack extends ArrayList {
...
}Implementation using composition:
class Stack {
private ArrayList elements;
...
}The implementation using inheritance is not recommended for two
reasons: (1) conceptually, a Stack is not an
ArrayList but a data structure that can use an
ArrayList in its implementation; (2) when inheritance is
used, Stack inherits methods like get and
set from ArrayList, which are not part of the
stack specification.
An additional benefit of composition is that the relationship between
the classes is not static, unlike in the case of inheritance. In the
inheritance-based implementation, Stack is statically
coupled to ArrayList, preventing runtime changes to this
decision. On the other hand, a composition-based solution allows for
such flexibility, as shown in the following example:
class Stack {
private List elements;
public Stack(List elements) {
this.elements = elements;
}
...
}In this example, the data structure for the stack elements is passed
as a parameter to the Stack constructor. This allows us to
create Stack objects with different data structures. For
instance, one stack could store elements in an ArrayList,
while another uses a Vector. It’s worth noting that the
Stack constructor receives a List parameter,
which is an interface type. Thus, this example also illustrates the
previous Prefer Interfaces to Classes principle.
Let’s conclude our presentation by summarizing three points:
Inheritance is classified as a white-box reuse mechanism, as subclasses typically have access to implementation details of the base class. In contrast, composition is a mechanism of black-box reuse.
The Decorator Pattern, which we will study in the next chapter, is a design pattern that facilitates replacing a solution based on inheritance with one based on composition.
In light of the problems discussed in this section, more recent programming languages, such as Go and Rust, have opted not to include support for class inheritance.
5.6.5 Demeter Principle 🔗
This principle is named after the Demeter research group at Northeastern University in Boston, USA, which conducted research on software modularization. In the late 1980s, this group proposed a set of rules to improve information hiding in object-oriented systems, which came to be known as the Law of Demeter or the Demeter Principle. The principle, also known as the Principle of Least Knowledge, asserts that a method’s implementation should only invoke methods:
- From its own class (case 1)
- From objects received as parameters (case 2)
- From objects created by the method itself (case 3)
- From attributes of the method’s class (case 4)
Example: In the following code, method
m1 makes four calls that respect the Demeter Principle. In
contrast, method m2 contains a call that violates the
principle.
class DemeterPrinciple {
T1 attr;
void f1() {
...
}
void m1(T2 p) { // method following Demeter
f1(); // case 1: own class
p.f2(); // case 2: parameter
new T3().f3(); // case 3: created by the method
attr.f4(); // case 4: class attribute
}
void m2(T4 p) { // method violating Demeter
p.getX().getY().getZ().doSomething();
}
}Method m2, by sequentially calling three
get methods, violates the Demeter Principle. This violation
occurs because the intermediate objects, returned by the getters, serve
as mere pass-through objects to reach the final object. In this example,
the final object is the one that provides a useful operation, named
doSomething(). However, the intermediate objects accessed
along the chain of calls may expose information about their state. Apart
from making the call more complex, the exposed information can change as
a result of future maintenance in the system. Thus, if one of the links
in the call sequence breaks, m2 would need to find an
alternative route to reach the final method. In summary, calls that
violate the Demeter Principle tend to break encapsulation since they
manipulate a sequence of objects, which are subject to changes.
To address this issue, the Demeter Principle advises that methods
should only communicate with their friends
, meaning either
methods of their own class or methods of objects they received as
parameters or created. On the other hand, it is not recommended to
communicate with friends of friends.
An example, formulated by David Bock (link), nicely illustrates the benefits of the Demeter Principle. The example involves three objects: a newspaper delivery person, a customer, and the customer’s wallet. A violation of the Demeter Principle occurs if, to receive the payment for a newspaper, the delivery person has to execute the following code:
price = 3.00;
Wallet wallet = customer.getWallet();
if (wallet.getTotalValue() >= price) { // violates Demeter
wallet.debit(price); // violates Demeter
} else {
// I'll be back tomorrow to collect the payment
}In this code, the delivery person has to access the customer’s
wallet, via getWallet(), and then directly retrieve the
bills to pay for the newspaper. However, it’s unrealistic to expect a
customer to allow a delivery person such direct access to their personal
wallet. A more realistic solution is the following:
price = 3.00;
try {
customer.pay(price);
} catch (InsufficientValueException e) {
// I'll be back tomorrow to collect the payment
}In this improved code, the customer does not give the delivery person
access to their wallet. On the contrary, the delivery person is
completely unaware that the customer has a wallet. This data structure
is encapsulated within the Customer class. Instead, the
customer offers a pay method, which is called by the
delivery person. An exception is thrown when the customer does not have
enough money to pay for the newspaper.
5.6.6 Open-Closed Principle 🔗
This principle, originally proposed by Bertrand Meyer in the 1980s (link), advocates an apparently paradoxical idea: a class must be closed to modifications but open to extensions.
However, this principle’s core concept is that developers should not only implement a class but also prepare it for future extensions and customizations. To achieve this, they can use parameters, inheritance, higher-order (or lambda) functions, and design patterns such as Abstract Factory, Template Method, and Strategy. These design patterns will be discussed in detail in the next chapter.
In short, the Open-Closed Principle recommends that, when appropriate, we should implement flexible and extensible classes that can adapt to various usage scenarios without requiring modifications to their source code.
Example 1: An example of a class that follows the
Open-Closed Principle is the Collections class in Java. It
has a static method that sorts a list in ascending order. Here’s an
example of using this method:
List<String> names;
names = Arrays.asList("john", "megan", "alexander", "zoe");
Collections.sort(names);
System.out.println(names);
// result: ["alexander", "john", "megan", "zoe"]However, we might later need to sort strings based on their length in
characters. Fortunately, the sort method is designed to
accommodate this new use case. To accomplish this, we need to implement
and pass as a parameter a function that compares the strings by their
length, as shown in the following code:
Collections.sort(names, (s1, s2) -> s1.length() - s2.length());
System.out.println(names);
// result: ["zoe", "john", "megan", "alexander"]This shows that the sort method is open to accommodating
this new requirement, while remaining closed, as we didn’t need to
modify the source code of the method.
Example 2: The following example shows a function that does not follow the Open-Closed Principle.
double calcTotalScholarships(Student[] list) {
double total = 0.0;
for (Student student : list) {
if (student instanceof UndergraduateStudent) {
UndergraduateStudent undergrad;
undergrad = (UndergraduateStudent) student;
total += "code that calculates undergrad scholarship";
}
else if (student instanceof MasterStudent) {
MasterStudent master;
master = (MasterStudent) student;
total += "code that calculates master scholarship";
}
}
return total;
}If in the future we need to create another subclass of
Student, for example, DoctoralStudent, the
code of calcTotalScholarships would need to be modified. In
other words, the function is not prepared to seamlessly accommodate
extensions for new types of students.
The Open-Closed Principle encourages class designers to anticipate
possible extension points. However, it’s important to highlight that it
is not feasible for a class to accommodate all potential extensions. For
instance, the sort method (Example 1) uses a version of the
MergeSort algorithm, but clients cannot customize this algorithm.
Therefore, in terms of configuring the sorting algorithm, the method
does not comply with the Open-Closed Principle.
5.6.7 Liskov Substitution Principle 🔗
As previously discussed in the Prefer Composition over
Inheritance
principle, inheritance has lost some of its popularity
since the 1980s. Today, the use of inheritance is more restrained and
less prevalent. However, certain use cases still justify its adoption.
Fundamentally, inheritance establishes an is-a
relationship
between subclasses and a base class. Its primary advantage lies in the
fact that methods common to all subclasses can be implemented only once,
in the base class. These methods are then inherited by all
subclasses.
The Liskov Substitution Principle establishes rules for redefining methods in subclasses. This principle’s name honors Barbara Liskov, an MIT professor and the recipient of the 2008 Turing Award. Among her various works, Liskov conducted research on object-oriented type systems. In one of her studies, she formulated the principle that later became named after her.
To explain the Liskov Substitution Principle, let’s begin with this code:
void f(B b) {
b.g();
...
}The f method can receive as argument objects of
subclasses S1, S2, …, Sn of the
base class B, as shown below:
f(new S1()); // f can receive objects from subclass S1
...
f(new S2()); // and from any subclass of B, such as S2
...
f(new S3()); // and S3The Liskov Substitution Principle defines the semantic conditions that subclasses must adhere to for a program to behave as expected.
Let’s consider that subclasses S1, S2, …,
Sn redefine the implementation of g()
inherited from the base class B. According to the Liskov
Substitution Principle, these redefinitions are possible, but they must
not violate the original contract of g as defined in the
base class B.
Example 1: Consider a PrimeNumber class
with methods for performing computations related to prime numbers. This
class has subclasses that implement alternative algorithms for the same
purpose. Specifically, the getPrime(n) method returns the
n-th prime number. This method is implemented in the
PrimeNumber class and redefined in its subclasses.
Let’s assume that the getPrime(n) contract specifies
that it should compute any prime number for the argument n
ranging from 1 to 1 million. In this context, a subclass would violate
this contract if its implementation of getPrime(n) only
handled prime numbers up to, for example, 900,000.
To further illustrate the principle, consider a client that calls
p.getPrime(n), where initially p references a
PrimeNumber object. Assume now that p is
substituted by an object from a subclass. Consequently, after the
substitution, the call will execute the getPrime(n)
implementation provided by this subclass. Essentially, the Liskov
Substitution Principle prescribes that this change in called methods
should not affect the client’s behavior. To achieve this, the
getPrime(n) implementations in the subclasses must perform
the same tasks as the original method, possibly more efficiently. For
example, they should accept the same input parameter range or a broader
one. However, they must not be redefined to accept a more restrictive
range than that provided by the base class implementation.
Example 2: Let’s present a second example that does not respect the Liskov Substitution Principle.
class A {
int sum(int a, int b) {
return a + b;
}
}class B extends A {
int sum(int a, int b) {
String r = String.valueOf(a) + String.valueOf(b);
return Integer.parseInt(r);
}
}class Client {
void f(A a) {
...
a.sum(1,2); // can return 3 or 12
...
}
}class Main {
void main() {
A a = new A();
B b = new B();
Client client = new Client();
client.f(a);
client.f(b);
}
}In this example, the method that adds two integers is redefined in
the subclass to concatenate the respective values after converting them
to strings. Therefore, a developer maintaining the Client
class may find this behavior confusing. In one execution, calling
sum(1,2) returns 3 (i.e., 1+2). In the subsequent
execution, the same call returns 12 (i.e., 1
+ 2
=
12
, or 12, converted to an integer).
5.7 Source Code Metrics 🔗
Over the years, various metrics have been proposed to quantify the properties of software design. Typically, these metrics require access to a system’s source code, meaning the project must already be implemented. By analyzing the structure of the source code, these metrics quantitatively express properties such as size, cohesion, coupling, and complexity, with the goal of assessing the quality of an existing design.
However, monitoring a system’s design using source code metrics is not a common practice nowadays. One of the reasons is that several design properties, such as cohesion and coupling, involve a degree of subjectivity, making their measurement challenging. Additionally, the interpretation of metric values is highly dependent on contextual information. A specific result might be acceptable in one system but not in another system from a different domain. Even among the classes within a given system, the interpretation of metric values can vary considerably.
In this section, we will describe metrics used to measure the following properties of a design: size, cohesion, coupling, and complexity. We will outline the steps for calculating these metrics and provide some examples. Before proceeding, it’s worth noting that there are also tools for calculating these metrics, including some that operate as plugins for well-known Integrated Development Environments (IDEs).
5.7.1 Size 🔗
One of the most popular source code metrics is Lines of Code (LOC). It can be used to measure the size of a function, class, package, or an entire system. When reporting LOC, it is important to specify which lines are actually counted. For example, whether comments or blank lines are included or not.
Although LOC provides an indication of a system’s size, it should not be used to measure developers’ productivity. For instance, if one developer implemented 1 KLOC in a week and another developer implemented 5 KLOC, we cannot conclude that the second developer was five times more productive. This is due to various factors, including the possibility that the requirements they implemented may have had different complexities. Ken Thompson, one of the developers of the Unix operating system, has an interesting quote about this topic:
One of my most productive days was throwing away 1,000 lines of code.
This quote is attributed to Thompson in a book authored by Eric Raymond, on page 24. Therefore, software metrics, regardless of their nature, should not be viewed as a goal in themselves. In the case of LOC, for example, this could encourage developers to duplicate code simply to meet a set goal.
Other size metrics include the number of methods, the number of attributes, the number of classes, and the number of packages.
5.7.2 Cohesion 🔗
A well-known metric for calculating cohesion is the Lack of Cohesion in Methods (LCOM). In general, for software metrics, a larger value indicates poorer code or design quality. However, cohesion is an exception to this rule, as higher cohesion indicates better design. For this reason, LCOM measures the lack of cohesion in classes. The larger the LCOM value, the higher the lack of cohesion within a class, and consequently, the poorer its design.
To calculate the LCOM of a class C, we should first compute the following set:
M(C) = { (f1, f2) | f1 and f2 are methods of C }
This consists of all unordered pairs of methods from class C. Next, we should compute the following set:
A(f) = Set of attributes accessed by method f
The value of LCOM(C) is defined as follows:
LCOM(C) = | { (f1, f2) in M(C) | A(f1) and A(f2) are disjoint sets } |
In other words, LCOM(C) is the number of method pairs within class C that don’t share common attributes.
Example: To illustrate the computation of LCOM, consider this class:
class A {
int a1;
int a2;
int a3;
void m1() {
a1 = 10;
a2 = 20;
}
void m2() {
System.out.println(a1);
a3 = 30;
}
void m3() {
System.out.println(a3);
}
}For this class, the following table shows the sets M and A, and the intersection of the A sets.
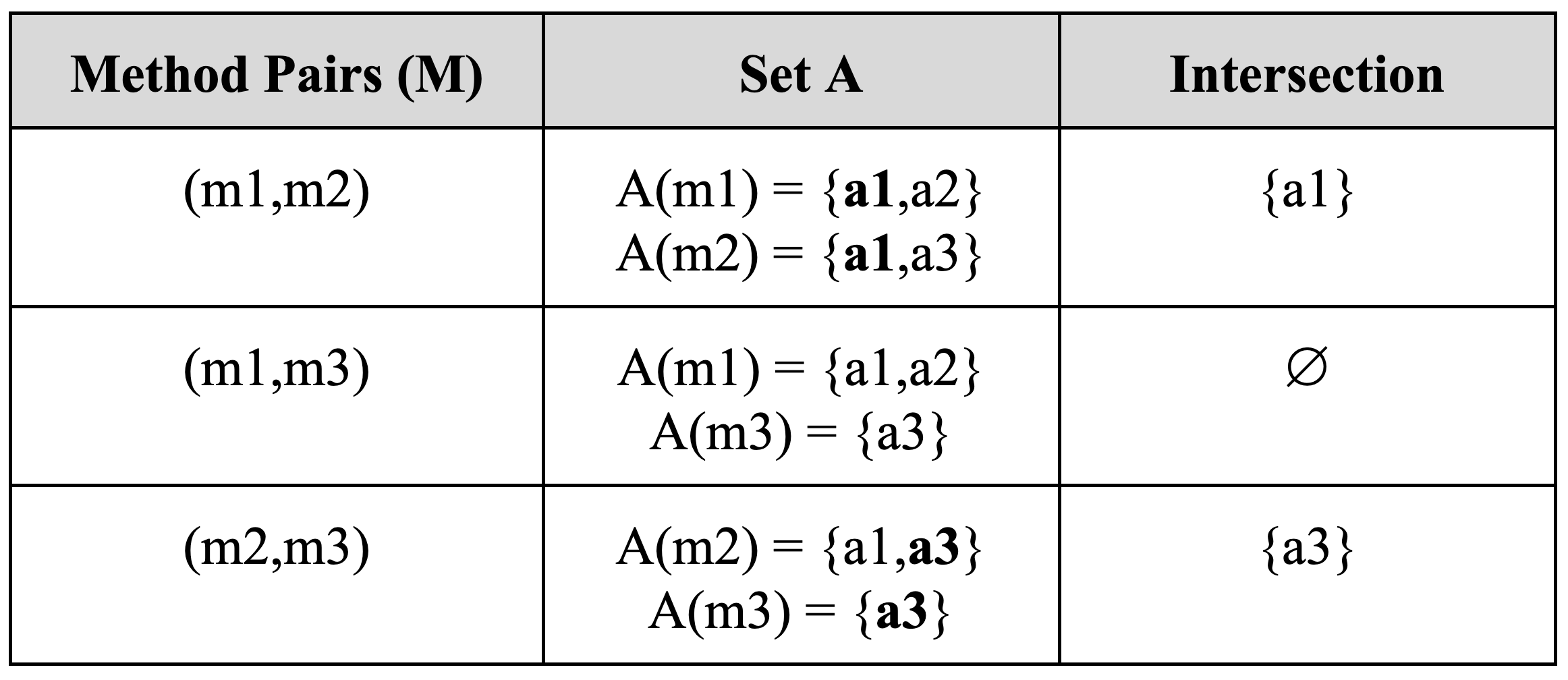
In this example, LCOM(C) equals 1. The class has three possible pairs of methods, but two pairs access at least one attribute in common (as shown in the third column of the table). Only one pair of methods does not share any common attributes.
LCOM assumes that, in a cohesive class, any pair of methods should access at least one common attribute. In other words, methods accessing the same attributes contribute to a class’s cohesion. Therefore, cohesion is compromised, i.e., LCOM increases by one, every time we find a pair of methods (f1, f2), where f1 and f2 manipulate completely different sets of attributes.
In LCOM calculation, constructors and getters/setters are typically excluded. Constructors often share attributes with most other methods, while the opposite tends to be true for getters and setters.
Lastly, it’s important to note that there are alternative proposals for calculating LCOM. The version we presented, known as LCOM1, was proposed by Shyam Chidamber and Chris Kemerer in 1991 (link). Other versions include LCOM2 and LCOM3. Therefore, when reporting LCOM values, it is important to clearly state which version of the metric is being used.
5.7.3 Coupling 🔗
Coupling Between Objects (CBO) is a metric for measuring structural coupling between classes. It was proposed by Chidamber and Kemerer (link and link).
Given a class A, CBO counts the number of classes on which A has syntactical (or structural) dependencies. Class A depends on a class B when any of the following conditions are met:
- A calls a method of B
- A accesses a public attribute of B
- A inherits from B
- A declares a local variable, parameter, or return type of type B
- A catches an exception of type B
- A throws an exception of type B
- A creates an object of type B
Suppose a class A with two methods (method1 and
method2):
class A extends T1 implements T2 {
T3 a;
T4 method1(T5 p) throws T6 {
T7 v;
...
}
void method2() {
T8 obj = new T8();
try {
...
}
catch (T9 e) { ... }
}
}As indicated by the distinct types that class A depends on (T1 through T9), we can see that CBO(A) = 9.
The definition of CBO does not distinguish between the target classes
responsible for the dependencies. For instance, it doesn’t differentiate
whether the dependency is on a class from the language’s standard
library (e.g., Hashtable) or a less stable class from an
application that is still under development.
5.7.4 Complexity 🔗
Cyclomatic Complexity (CC) is a metric proposed by Thomas McCabe in
1976 to measure the complexity of code within a function or method (link). It is commonly
referred to as McCabe’s Complexity. In the context of this metric,
complexity relates to the difficulty of maintaining and testing a
function. The definition of CC is based on the concept of control flow
graphs. In these graphs, the nodes represent the statements in a
function or method, and the edges represent possible control flows. For
example, control structures like an if statement generate
two control flows. The metric’s name derives from the fact that it is
calculated using a concept from Graph Theory called the cyclomatic
number.
However, there’s a simple alternative method to calculate a function’s CC, which doesn’t require control flow graphs. This alternative defines CC as follows:
CC = number of decision statements in a function
+
1
Decision statements include if, while,
case, for, etc. The intuition behind this
formula is that these constructs make the code harder to understand and
test and, hence, more complex.
Therefore, calculating CC is straightforward: count the number of
decision statements in a function’s source code and add 1. The lowest CC
value is 1, which occurs in code that contains no decision statements.
In the article where he defined the metric, McCabe suggests that a
reasonable but not magic upper limit
for CC is 10.
Bibliography 🔗
Robert C. Martin. Clean Architecture: A Craftsman’s Guide to Software Structure and Design, Prentice Hall, 2017.
John Ousterhout. A Philosophy of Software Design, Yaknyam Press, 2nd edition, 2021.
Erich Gamma, Richard Helm, Ralph Johnson and John Vlissides. Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley, 1995.
Frederick Brooks. The Mythical Man-Month: Essays on Software Engineering. Addison-Wesley, Anniversary Edition, 1995.
Diomidis Spinellis. Code Quality. Addison-Wesley, 2006.
Andrew Hunt, David Thomas. The Pragmatic Programmer: From Journeyman to Master. Addison-Wesley, 2nd edition, 2019.
Mauricio Aniche. Orientação a Objetos e SOLID para Ninjas. Projetando classes flexíveis. Casa do Código, 2015. (in Portuguese)
Thomas J. McCabe. A Complexity Measure. IEEE Transactions on Software Engineering, vol. 2, issue 4, p. 308-320, 1976.
Shyam Chidamber, Chris Kemerer. A Metrics Suite for Object Oriented Design. IEEE Transactions on Software Engineering, vol. 20, issue 6, p. 476-493, 1994.
Shyam Chidamber, Chris Kemerer. Towards a Metrics Suite for Object Oriented Design. ACM SIGPLAN International Conference on Object-oriented Programming Systems, Languages, and Applications (OOPSLA), p. 197-211, 1991.
Exercises 🔗
1. Describe three advantages of information hiding.
2. Suppose there are two classes, A and B, that are implemented in different directories; class A has a reference in its code to class B. Moreover, whenever developers need, as part of a maintenance task, to modify both classes A and B, they finish the task by moving B to the same directory as A. (a) By acting in this way, which design property (when measured at the level of directories) are the developers improving? (b) Which design property (also measured for directories) is negatively affected?
3. Classitis is a term used by John Ousterhout to describe the
proliferation of small classes in a system. According to him, classitis
results in classes that are individually simple but collectively
increase the total complexity of a system. Using the concepts of
coupling and cohesion, explain the problem caused by this
disease.
4. Define: (a) acceptable coupling; (b) poor coupling; (c) structural coupling; (d) evolutionary (or logical) coupling.
5. Give an example of: (1) acceptable and structural coupling; (2) poor and structural coupling.
6. Is it possible for class A to be coupled with class B without having a reference to B in its code? If so, is this coupling acceptable, or is it a case of poor coupling?
7. Suppose there is a program where all the code is implemented in
the main method. Does it have a cohesion or coupling
problem? Justify your answer.
8. Object-oriented programming is built on three key concepts: encapsulation, polymorphism, and inheritance. Suppose you were tasked with designing a new object-oriented language, but could only include two of these three concepts. Which concept would you eliminate from your language? Justify your answer.
9. What design principle is not followed by this code?
void onclick() {
id1 = textfield1.value(); // presentation
account1 = BD.getAccount(id1);
id2 = textfield2.value();
account2 = BD.getAccount(id2);
value = textfield3.value(); // non-functional req.
beginTransaction();
try {
account1.withdraw(value); // business rule
account2.deposit(value);
commit();
}
catch() {
rollback();
}
} 10. What design principle is not followed by this code? How would you modify the code to follow this principle?
void sendMail(BankAccount account, String msg) {
Customer customer = account.getCustomer();
String address = customer.getMailAddress();
"code that sends the mail"
} 11. What design principle is not followed by this code? How would you modify the code to follow this principle?
void printHiringDate(Employee employee) {
Date date = employee.getHireDate();
String msg = date.format();
System.out.println(msg);
} 12. The preconditions of a method are boolean expressions involving its parameters (and possibly the state of the class) that must be true before its execution. Similarly, postconditions are boolean expressions involving the method’s result. Considering these definitions, which design principle is violated by this code?
class A {
int f(int x) { // pre: x > 0
...
return exp;
} // pos: exp > 0
}class B extends A {
int f(int x) { // pre: x > 10
...
return exp;
} // pos: exp > -50
}13. Calculate the CBO and LCOM of the following class:
class A extends B {
C f1, f2, f3;
void m1(D p) {
"uses f1 and f2"
}
void m2(E p) {
"uses f2 and f3"
}
void m3(F p) {
"uses f3"
}
}14. Which of the following classes is more cohesive? Justify your answer by calculating the LCOM values for each class.
class A {
X x = new X();
void f() {
x.m1();
}
void g() {
x.m2();
}
void h() {
x.m3();
}
}class B {
X x = new X();
Y y = new Y();
Z z = new Z();
void f() {
x.m();
}
void g() {
y.m();
}
void h() {
z.m();
}
}15. Why does LCOM measure the lack and not the presence of cohesion? Justify your answer.
16. Should all methods of a class be considered in the LCOM calculation? Yes or no? Justify your answer.
17. Is the definition of cyclomatic complexity independent of the programming language? True or false? Justify.
18. Provide an example of a function with minimum cyclomatic complexity. What is this minimum complexity?
19. Cristina Lopes is a professor at the University of California, Irvine, USA, and the author of a book about programming styles (link). She discusses in the book several implementations of the same problem, called term frequency. Given a text file, the program should list the n-most frequent words in descending order of frequency, ignoring stop words, i.e., articles, prepositions, etc. The Python source code for all implementations discussed in the book is publicly available on GitHub (and for this exercise, we made a fork of the original repository). Analyze the following two versions:
First, review the code of both versions (each version is under 100 lines). Then, discuss the advantages of the object-oriented solution over the monolithic one. To do this, consider the implications for a large system. For example, how might the different approaches affect development in a scenario where the system is implemented by different developers, and each one is responsible for a part of the project?