
Software Engineering: A Modern Approach
10 DevOps 🔗
Imagine a world where product owners, development, QA, IT Operations, and Infosec work together, not just to aid each other, but to guarantee the overall success of the organization. – Gene Kim, Jez Humble, Patrick Debois, John Willis
This chapter begins by discussing the concept of DevOps and its
benefits (Section 10.1). Essentially, DevOps is a movement—or more
specifically, a set of concepts and practices—aimed at introducing agile
principles in the last mile
of a software project, i.e., when the
system is entering production. In addition to discussing the concept, we
address three key practices for adopting DevOps: version control
(Section 10.2), continuous integration (Section 10.3), and continuous
deployment (Section 10.4).
10.1 Introduction 🔗
Throughout this book, we have studied a set of practices for high-quality and agile software development. From agile methods, like Scrum, XP, and Kanban, we learned that clients should be involved from day one in the software development process. We also discussed key practices for producing high-quality software, such as unit testing and refactoring. Additionally, we examined several design principles and patterns.
After applying these practices, principles, and patterns, the software product—or an increment of it resulting from a sprint—is ready for production. This process is known as deployment, release, or delivery. However, regardless of the term used, it is not as straightforward as it may seem.
Traditionally, in conventional organizations, the information technology area was divided into two main departments:
Development Department, composed of developers, analysts, architects, and others.
Operations Department, composed of system and network administrators, database administrators, support technicians, site reliability engineers, and others. These professionals are responsible for installing, configuring, and maintaining an organization’s operating systems, networks, hardware, and cloud infrastructures. They ensure these resources are consistently available, reliable, and high-performing.
Today, the problems caused by this division are well-documented. Typically, the support team would become aware of a system only on the eve of its deployment. Consequently, the deployment might be postponed for months due to a variety of unaddressed issues, such as inadequate hardware, performance problems, incompatibility with the production database, and security vulnerabilities. In extreme cases, these problems could result in the cancellation of the deployment and the abandonment of the project.
In summary, in this traditional model, a significant stakeholder—the system administrators or sysadmins—would only become aware of the characteristics and non-functional requirements of the new software shortly before deployment. This issue was exacerbated by systems following a monolithic architecture, where deployment could create various concerns, including bugs and regressions in previously working modules.
Therefore, to facilitate the deployment and delivery of software, the DevOps concept was proposed. As it is a relatively recent term, it still lacks a single widely accepted definition. However, DevOps is commonly described as a movement that aims to bridge the development (Dev) and operations (Ops) cultures, enabling faster and more agile software deployments. This objective is reflected in the quote that opens this chapter, from Gene Kim, Jez Humble, Patrick Debois, and John Willis, key figures who helped establish DevOps principles. According to them, DevOps represents a disruption in traditional software deployment culture (link):
Instead of starting deployments at midnight on Friday and spending the weekend working to complete them, deployments occur on any business day when everyone is in the company and without customers noticing—except when they encounter new features and bug fixes.
However, DevOps does not advocate the creation of a new professional role responsible for both development and deployment. Instead, its goal is to foster a closer relationship between the development and operations teams, aiming to make software deployment more agile and less traumatic. In other words, the aim is to avoid creating two independent silos, developers and operators, with little to no interaction between them, as illustrated in the following figure.

Instead, DevOps advocates argue that these professionals should work together from the early sprints of a project, as illustrated in the following figure. For the customers, the benefit should be the earlier delivery of the contracted software project.

When transitioning to a DevOps culture, agile teams can incorporate an operations professional, who engages in the work either part-time or full-time. Depending on the demand, this professional may contribute to multiple teams. As part of their work, they proactively address performance issues, security concerns, incompatibilities with other systems, and other operational problems. They also collaborate on the installation, administration, and monitoring scripts for the production software.
DevOps strongly advocates automating all necessary steps to put a system into production and to monitor its operation. This requires the adoption of practices we have already studied in this book, notably automated tests. Furthermore, it also recommends the use of new practices and tools, such as Continuous Integration and Continuous Deployment, which we will examine later in this chapter.
Real World: The term DevOps began to be used in the late 2000s by professionals frustrated with the constant friction between development and operations teams. They became convinced that the solution lay in adopting agile principles not only in development but also in the deployment phase. To provide a specific reference point, the first industry conference on the topic, called DevOpsDays, took place in Belgium in November 2009. It is generally accepted that the term DevOps was coined at this conference, which was organized by Patrick Debois (link).
Finally, we’ll discuss a set of principles for software delivery proposed by Jez Humble and David Farley (link). Although these principles were proposed before DevOps gained traction, they align closely with this movement. The key principles include:
Create a repeatable and reliable process for software delivery. The goal is to ensure that software delivery does not become a stressful event, filled with manual steps and surprises. Instead, it should be as simple as clicking a button.
Automate as much as possible. This principle is, in fact, a prerequisite for the previous one. It advocates that all delivery steps should be automated, including building executables, running tests, configuring and deploying virtual machines or containers, creating and initializing databases, and so on. Ideally, the goal is to press a button and see the software deployed in production.
Keep everything in a version control system.
Everything
here refers not only to the source code but also to configuration files, scripts, documentation, web pages, wikis, images, and other project assets. Thus, it should be simple to restore and revert the system to a previous state. We will study the basic concepts of Version Control in Section 10.2. Additionally, in Appendix A, we provide an introduction to Git commands, which is currently the most popular version control system in use.If a step causes pain, execute it frequently and as early as possible. The goal is to anticipate problems before they accumulate and become difficult to solve. The classic example is Continuous Integration. If developers work in isolation for extended periods, they will likely face significant challenges when integrating their code later. Therefore, as integration often causes pain, the recommendation is to integrate new code as soon as possible, ideally daily. We will explore Continuous Integration in more detail in Section 10.3.
Done
means ready for delivery. Developers often declare a user story asdone
. However, when asked if it is ready for production, minor issues often emerge, such as the following: the implementation hasn’t been tested with real data, it lacks documentation, or it isn’t integrated with an important third-party system. Therefore, this principle emphasizes thatdone
in software projects should have a clear meaning: fully ready for delivery.Everyone is responsible for software delivery. Thus, it is no longer acceptable for the development and operations teams to work in isolated silos and to only share information immediately before an important deployment.
10.2 Version Control 🔗
As we have mentioned numerous times in this book, software is
developed in teams. Therefore, we need a repository, which is a server
that stores the source code of the system being implemented by these
teams. The existence of this server is vital for developers to
collaborate and for operators to know precisely which version of the
system should be deployed to production. Moreover, it keeps a history of
the most important versions of each file, enabling developers to
undo
changes and recover the code of a file as it was in the
past, even years ago, if needed.
A Version Control System (VCS) offers the services mentioned above. First, it provides a repository to store the most recent version of a system’s source code, as well as related files, such as documentation files, configuration files, web pages, wikis, etc. Second, it allows the retrieval of older versions of any file, if necessary. As emphasized earlier, it is inconceivable in modern software development to create any system, no matter how simple, without a VCS.
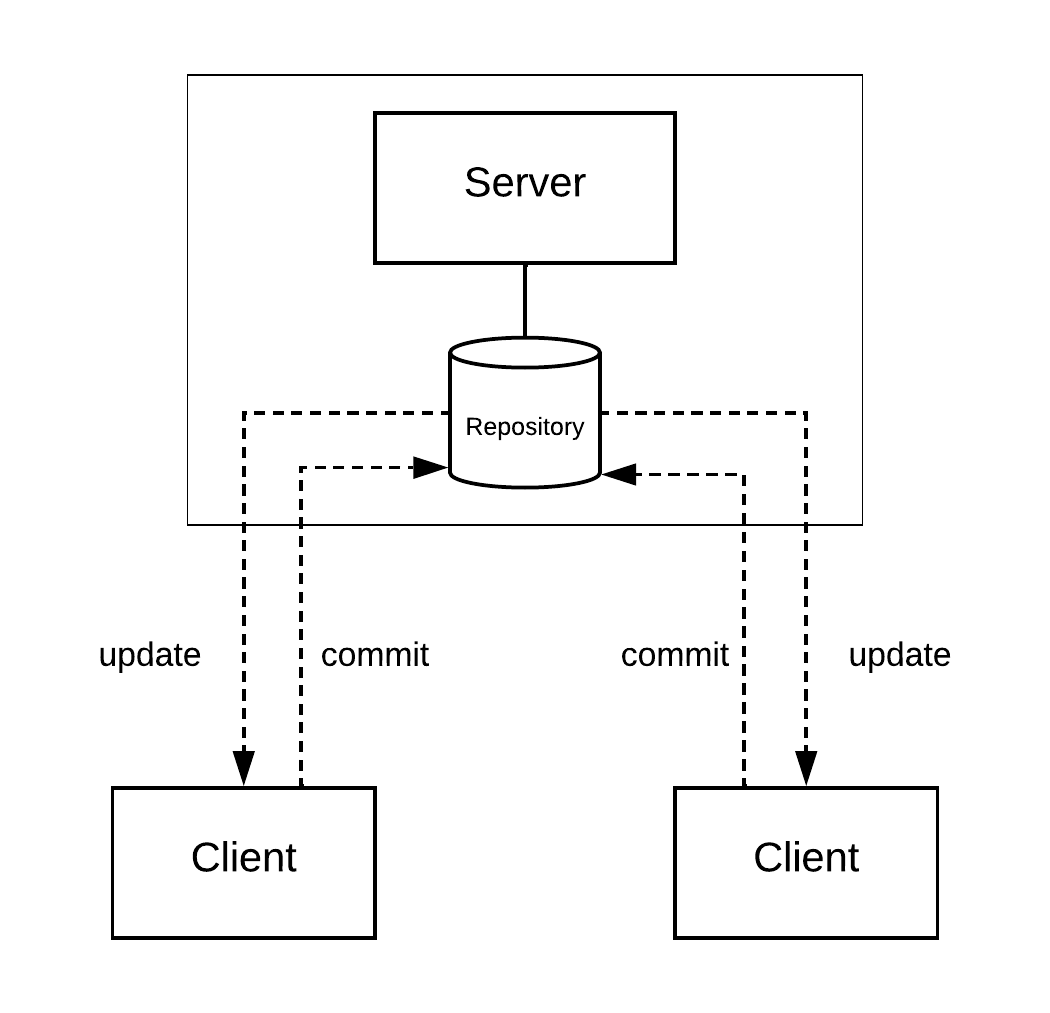
The first version control systems emerged in the early 1970s, such as the SCCS system, developed for the Unix operating system. Subsequently, other systems appeared, including CVS in the mid-1980s, and later the Subversion system, also known by its acronym SVN, in the early 2000s. Both CVS and SVN are centralized systems based on a client/server architecture (see the next figure). In this architecture, a single server stores the repository and the version control system. Clients access this server to obtain the most recent version of a file. They can then modify the file, for example, to fix a bug or implement a new feature. Finally, they update the file on the server, performing an operation called a commit, which makes the file visible to other developers.
In the early 2000s, Distributed Version Control Systems (DVCS) began to emerge. Among them, we can mention the BitKeeper system, whose first release was in 2000, and the Mercurial and Git systems, both launched in 2005. Instead of a client/server architecture, a DVCS employs a peer-to-peer architecture. In practice, this means that each developer has a full version control system on their own machine, which can communicate with systems on other machines, as illustrated in the next figure.

In theory, when using a DVCS, the clients (or peers) are functionally equivalent. However, in practice, there is usually a primary machine that holds the reference version of the source code. In our figure, we refer to this repository as the central repository. Each developer can work independently and even offline on their workstation, making commits to their local repository. Periodically, they should synchronize this repository with the central one through two operations: pull and push. A pull operation updates the local repository with new commits available in the central repository. Conversely, a push operation sends the latest commits made by the developers in their local repository to the central one.
Compared to centralized VCSs, a DVCS has the following advantages:
Developers can work and manage versions offline, without being connected to a network, as commits are first performed on the repository installed on the developer’s machine.
Developers can make commits frequently, including those with partial implementations, as these commits won’t immediately reach the central repository.
Commits are executed more quickly, as they are faster and lighter operations since they are made on the local repository.
Synchronization does not always need to occur with the central repository. For instance, a hierarchical structure of repositories can be established. In this case, the commits performed in the repositories representing the leaves should move upward until they reach the central repository.
Git is a distributed version control system developed under the leadership of Linus Torvalds, who is also responsible for creating the Linux operating system. In its early years, the development of the Linux kernel used a commercial version control system called BitKeeper, which also followed a distributed architecture. However, in 2005, the company that owned BitKeeper decided to revoke the free licenses used in the development of Linux. The Linux developers, led by Torvalds, then decided to create their own DVCS, which they named Git. Like Linux, Git is an open-source system that can be freely installed on any machine. Git is primarily a command-line tool. However, there are third-party graphical clients that allow using Git without typing commands.
GitHub is a code hosting service that uses the Git system to provide version control. Thus, rather than maintaining a DVCS internally, a software company can subscribe to GitHub’s service. A comparison can be drawn with email services: instead of installing an email server locally, a company typically uses third-party services, like Google Gmail. Although GitHub is the most popular, similar services are provided by other companies, such as GitLab and Bitbucket.
In Appendix A, we present and illustrate the main commands of the Git system. Additionally, we explain concepts specific to GitHub, such as forks and pull requests.
10.2.1 Multi-repos vs Monorepos 🔗
As we mentioned earlier, a VCS manages repositories. Therefore, an organization needs to decide how many repositories it will create in its VCS. A common approach is to create one repository for each project or system in the organization. However, approaches based on a single repository are also possible and are often adopted by large companies, such as Google, Meta, and Microsoft. These approaches—referred to as multi-repos and monorepos, respectively—are illustrated in the following figures.


In terms of GitHub accounts and repositories, the following examples
illustrate the idea (assuming an organization called my-org
):
In a multi-repo approach, the organization will have multiple repositories, such as
my-org/system1,my-org/system2,my-org/system3, etc.In a monorepo approach, the organization will have a single repository—for example,
my-org/my-org. In the root directory of this repository, there will be subdirectoriessystem1,system2,system3, etc.
The advantages of monorepos include:
With a single repository, there is no doubt about which repository holds the latest version of a file. In other words, with monorepos, there is a single
source of truth
regarding source code versions.Monorepos encourage code reuse and sharing, as developers have easy access to files from any project.
Changes across multiple projects can be made atomically. With multi-repos, two commits are required to make a change that affects two systems. With monorepos, the same change can be made with a single commit.
Monorepos facilitate large-scale refactorings. For example, consider renaming a function that is called by all of an organization’s systems. With monorepos, this renaming can be accomplished with a single commit.
On the other hand, monorepos require specific tools to manage and navigate large codebases. For example, those responsible for Google’s monorepo have reported that they had to implement a plugin for the Eclipse IDE to facilitate working with their very large codebase (link).
10.3 Continuous Integration 🔗
We begin with a motivational example before introducing the concept of Continuous Integration (CI). Subsequently, we discuss complementary practices that an organization should adopt along with CI. We conclude with a brief discussion about scenarios that may discourage the use of CI in an organization.
10.3.1 Motivation 🔗
Before defining Continuous Integration, let’s describe the problem that led to the proposal of this integration practice. Traditionally, developers often use branches when implementing new features. Branches can be understood as internal and virtual sub-directories, managed by the version control system. In these systems, there is a principal branch, known as main (when using Git) or trunk (when using other systems, such as SVN). In addition to the main branch, users can create their own branches.
For example, before implementing a new feature, developers often create a branch to hold its code. These branches are called feature branches, and depending on the complexity of the feature, they may take months to be merged back into the main development line. In fact, in large and complex projects, there can be dozens of active feature branches.
When the new feature is completed, its code must be integrated back into the main branch using a command called merge, provided by the version control system. However, this process can lead to a variety of conflicts, known as integration or merge conflicts.
To illustrate, let’s consider a scenario where Alice created a branch to implement a new feature X in her system. Due to the feature’s complexity, Alice worked in isolation on her branch for 40 days, as shown in the following figure (where each node of the graph represents a commit). Note that while Alice was working and committing changes on her branch, commits were also being made on the main branch.

After 40 days, when Alice merged her code into the main branch, numerous conflicts arose, such as:
To implement feature X, Alice’s code uses a function
f1, which existed in the main branch at the time of the feature branch creation. However, during the 40-day period, other developers changed the signature of this function in the main branch. For instance, the function was renamed or received a new parameter. In a more radical scenario, it might have been removed from the main development line.To implement feature X, Alice changed the behavior of a function
f2. For example,f2used to return a result in miles, but Alice changed it to return results in kilometers. She updated the code that callsf2to consider this new unit. However, during the 40-day period, other developers introduced new calls tof2in the code, which were integrated into the main branch while still assuming the result was in miles.
In large systems, with thousands of files, dozens of developers, and several feature branches, the problems caused by conflicts can take on considerable proportions and delay the deployment of new features. Note that conflict resolution is a manual task, requiring analysis and consensus among the developers involved. This explains why the terms integration hell or merge hell are commonly used to describe the problems related to the integration of feature branches.
Long-lived feature branches can also create knowledge silos, with each new feature having a de facto owner who may work on it in isolation for weeks. Therefore, this developer may feel comfortable adopting different patterns than the rest of the team, including architectural and design patterns, code layout patterns, and user interface patterns.
10.3.2 What is Continuous Integration? 🔗
Continuous Integration (CI) is a software development practice that originated from Extreme Programming (XP). The motivation behind this practice was already discussed in the first section of this chapter: if a task causes pain, we should not let it accumulate. Instead, we should break it into subtasks that can be performed frequently. Because these subtasks are small and simple, they cause less pain.
In our context, large integrations are a major source of pain for developers, as they have to manually resolve multiple conflicts. Therefore, CI recommends integrating the code frequently, that is, continuously. As a result, the integrations will be small and will produce fewer conflicts.
In his XP book, Kent Beck advocates the use of CI as follows (link, page 49):
Integrate and test changes after no more than a couple of hours. Team programming isn’t a divide-and-conquer problem. It’s a divide, conquer, and integrate problem. The integration step can easily take more time than the original programming. The longer you wait to integrate, the more it costs and the more unpredictable the cost becomes.
In this quote, Beck recommends multiple integrations throughout a developer’s workday. However, this recommendation is not universally accepted. Other authors, such as Martin Fowler, suggest at least one integration per day per developer (link), which seems to be a minimum threshold for a team to claim that it is using CI.
10.3.3 Best Practices When Using CI 🔗
When using CI, the main branch is constantly updated with new code. To ensure that it is not broken—that is, to ensure that the code compiles and runs successfully—some practices should accompany CI, as discussed next.
Automated Builds 🔗
The build is the process of compiling and producing an executable version of a system. When using CI, this process must be automated; that is, it should not include manual steps. Furthermore, it should be as quick as possible, since with CI builds are executed continuously. Some authors, for example, recommend a limit of 10 minutes for a build (link).
Automated Tests 🔗
In addition to ensuring that the system compiles without errors after a new integration, it is also important to verify that it continues to run correctly and produce the expected results. Therefore, when using CI, we should maintain good test coverage, particularly through unit tests, as discussed in Chapter 8.
Continuous Integration Servers 🔗
Automated builds and tests should be executed frequently, preferably before code is integrated into the main branch. To achieve this, we can use CI Servers, which work as follows (also see the following figure):
Before a new commit reaches the main branch, the version control system notifies the CI server, which clones the repository, performs a build, and runs the tests.
The CI server then notifies the commit author about any build errors or failing tests.

The main goal of a CI server is to prevent the integration of code containing errors, including both compilation and logic errors. For example, a build may succeed on the developer’s machine, but fail when executed on the CI server. This can occur, for instance, when the developer forgets to commit a file. Incorrect dependencies are another common reason for build failures. As an example, the code might be compiled and tested on the developer’s machine using version 2.0 of a certain library, while the CI server performs the build using version 1.0.
Several Continuous Integration servers are available on the market. Some of them are offered as independent services, typically free for public repositories, but requiring payment for private ones.
Another question is whether CI is compatible with feature branches. To maintain consistency with the definition of CI, the best answer is yes, provided that the branches are frequently integrated into the main branch, for example, every day. In other words, CI is incompatible only with long-lived feature branches.
Trunk-Based Development 🔗
As we’ve seen, when adopting CI, branches should last for a maximum of one working day. Therefore, the cost-benefit of creating them may not be worth it. For this reason, when shifting to CI, it’s common to also adopt Trunk-Based Development (TBD). With TBD, there are no longer branches for new features or bug fixes (or they exist only in the developer’s local repository and are therefore short-lived). As a result, all development takes place on the main branch, also known as the trunk.
Real World: TBD is used by major software companies.
For example, at Google, almost all development occurs at the HEAD of
the repository, not on branches. This helps identify integration
problems early and minimizes the amount of merging work needed. It also
makes it much easier and faster to push out security fixes
(link). Similarly, at
Facebook (now Meta), all front-end engineers work on a single stable
branch of the code, which also promotes rapid development, since no
effort is spent on merging long-lived branches into the trunk
(link).
Pair Programming 🔗
Pair Programming can be viewed as a continuous code review practice. When adopting this practice, any new code is reviewed by another developer, who sits next to the lead developer during the programming session. As with continuous builds and tests, Pair Programming is often recommended alongside CI. However, this practice is not mandatory. For example, the code can be reviewed after the commit reaches the mainline. In this case, because the code is visible to other developers and can be moved into production at any time, the cost of applying a review tends to be higher.
10.3.4 When not to use CI? 🔗
CI proponents set a firm limit for integrations on the main branch: at least one integration per day per developer. However, depending on the organization, system domain (which may be a safety-critical application, for instance), and the developers’ profiles (who might be beginners), it can be challenging to follow this limit.
Moreover, this limit is not a law of physics. For example, it may be worthwhile to perform an integration every two or three days. In fact, any software engineering practice—including Continuous Integration—should not be applied literally, that is, exactly as it is described in a manual or textbook. Context-justified adaptations are not only possible but should be carefully considered. Therefore, experimenting with different integration intervals can help define the best setup for your organization.
CI is often not compatible with open-source software projects. Frequently, the developers of these projects are volunteers and do not work on the code daily. In these cases, a model based on pull requests and forks, as popularized by GitHub, is better suited. We provide more details about these concepts in Appendix A.
10.4 Continuous Deployment 🔗
With Continuous Integration, new code is frequently integrated into the main branch. However, this code isn’t necessarily ready for production. Rather, it can be a preliminary version, integrated so that other developers become aware of its existence and, consequently, avoid future integration conflicts. For instance, you can integrate a preliminary version of a web page with a basic interface, or a feature with known performance issues.
Beyond Continuous Integration, DevOps proposes another step in the automation chain, called Continuous Deployment (CD). The difference between CI and CD is simple, but the impacts are profound: when using CD, every new commit that reaches the main branch is deployed to production, typically within a matter of hours, for instance. Specifically, the workflow with CD is as follows:
The developer implements new code and tests it on their local machine.
They make a commit and the CI server immediately reruns the unit tests.
Several times a day, the CI server runs additional tests on commits that have not yet been deployed to production. These tests may include integration, end-to-end, and performance tests, among others
If all the tests pass, the commits are deployed to production, and customers gain access to the new version of the code.
Among the advantages of CD, we can mention:
CD reduces the delivery time of new features. For example, suppose features F1, F2,…, Fn are planned for a new release. In the traditional mode, they will be deployed at the same time, even if F1 becomes ready weeks before Fn. With CD, however, the features are released as soon as they are ready. Consequently, CD reduces the interval between releases. This results in more releases, but with fewer features per release.
CD makes new releases (or deployments) a non-event. This means there are no longer deadlines for delivering new releases. Deadlines are a source of stress for developers and operations teams. Missing a deadline, for example, can delay a feature’s entry into production by months.
CD not only reduces the stress caused by deadlines but also helps keep developers motivated, as they don’t spend months working without feedback. Instead, developers quickly receive input from real customers regarding the success or failure of their features.
Furthermore, CD promotes experimentation and a development style driven by data and customer feedback. New features are rapidly deployed into production. As a result, developers continuously receive feedback from customers, who can recommend changes to their implementations. In extreme cases, developers can even decide to cancel certain features.
Real World: Various companies that develop web apps use CD. For instance, in an article published in 2016, Savor and colleagues reported that at Facebook, each developer, on average, deployed 3.5 updates into production per week (link). These updates added or modified an average of 92 lines of code. This data suggests that to work effectively, CD requires small updates. Therefore, developers must learn to break down a programming task (e.g., a new feature, even if complex) into small parts, which can be quickly implemented, tested, and deployed.
10.4.1 Continuous Delivery 🔗
Continuous Deployment (CD) is not suitable for certain types of systems, such as desktop apps (like an IDE or a web browser) and embedded software (like a printer driver). Users typically don’t want to be notified daily about a new version of their browser or that a new driver is available for their printer. These systems require an installation process that is not transparent to users, unlike web system updates.
However, in such cases, a variant known as Continuous Delivery can be used. The idea is straightforward: with Continuous Delivery, every push is prepared for immediate deployment to production. However, an external authority—such as a project manager or a release manager— decides when these versions will actually be released to customers. Marketing and corporate strategies are examples of forces that can influence this decision.
To clarify the distinction between these practices:
Deployment is the process of releasing new software versions to customers.
Delivery is the process of preparing new software versions for potential deployment.
In Continuous Deployment, both processes are automatic and continuous. However, with Continuous Delivery, delivery is performed frequently, while deployment requires manual authorization.
Whether adopting Continuous Deployment or Delivery, software
companies are increasingly reducing their release cycles to keep users
engaged, receive feedback, maintain developer motivation, and remain
competitive in the market. This trend is evident even in desktop apps.
For example, as of 2024, Google releases a major version of the Chrome
browser every four weeks. Additionally, weekly updates are used to
deploy security fixes to keep Chrome’s patch gap short.
10.4.2 Feature Flags 🔗
However, it is unrealistic to assume that every commit will be ready for immediate deployment. For example, a developer may be working on a new feature X but still need to implement part of its logic. In such a situation, the developer may ask:
If new releases happen almost every day, how can I prevent my unfinished implementation, which has not been properly tested and has critical performance issues, from reaching the company’s customers?
A potential solution is to refrain from integrating the code into the main development branch. However, this practice is no longer recommended, as it leads to what is known as integration or merge hell. In other words, we don’t want to give up Continuous Integration and Trunk-Based Development.
A more pragmatic solution to this problem is to continuously integrate the partial code of feature X, but with its execution disabled, ensuring that any code related to X is guarded by a boolean variable (or flag) that evaluates to false until the implementation is finished. An example is shown below:
featureX = false;
...
if (featureX)
"here is my incomplete code for X"
...
if (featureX)
"more incomplete code for X"In the context of Continuous Deployment, variables used to prevent the deployment of partial implementations are called feature flags or feature toggles.
To further illustrate, consider another example. Suppose you’re working on a new page for a web application. You can use a feature flag to enable or disable this page, as shown below:
new_page = false;
...
if (new_page)
"show new page"
else
"show old page"This code can be safely deployed while the new page is not ready.
However, during development, you can enable the new page locally by
setting the new_page flag to true.
This approach results in code duplication between the two pages for a
period of time. However, after the new page is approved, deployed, and
receives positive feedback from customers, the old page’s code and the
feature flag (new_page) can be removed. Thus, the
duplication is temporary.
Real World: Researchers from two Canadian universities, led by Professors Peter Rigby and Bram Adams, conducted a study on the use of feature flags across 39 releases of the Chrome browser, covering five years of development, from 2010 to 2015 (link). During this period, they identified more than 2,400 distinct feature flags in Chrome’s code. In the first version analyzed, they documented 263 flags; in the last version, the number had increased to 2,409. On average, each new release introduced 73 flags and removed 43, resulting in the net increase observed in the study.
However, feature flags can be retained in the code beyond the deployment phase. This can occur for two reasons, as described below.
First, feature flags help implement what is called a canary release. In this type of release, a new feature—guarded by a feature flag—is initially made available to a small group of users, for example, only 5% of the user base. This approach minimizes any problems caused by potential bugs in this new feature. After a successful initial deployment, the percentage of users with access to the new feature is gradually increased until it reaches all users. The term canary release refers to a historical practice used in the exploration of coal mines. Miners would carry a canary in a cage into the mines. If the mine contained any toxic gas, it would kill the canary, alerting the miners to withdraw to prevent intoxication.
Second, feature flags facilitate the implementation of A/B Tests, as discussed in Chapter 3. To recap, in these tests, two versions of a feature (old versus new version, for instance) are simultaneously released to distinct user groups, aiming to verify if the new feature actually provides additional value to the current implementation.
To facilitate the execution of canary releases and A/B tests, a data structure can be used to store the flags and their state (on or off). An example is shown below:
FeatureFlagsTable fft = new FeatureFlagsTable();
fft.addFeature("new-shopping-cart", false);
...
if (fft.isEnabled("new-shopping-cart"))
// process purchase using new cart
else
// process purchase using current cart
... There are also libraries dedicated to managing feature flags, which
provide classes similar to FeatureFlagsTable shown in the
previous example. The advantage of these libraries is that the flags can
be set externally to the program, for example, through a configuration
file. On the other hand, when the flag is an internal boolean variable,
changing its value requires editing the source and recompiling the
code.
In-Depth: In this section, we focused on the use of feature flags to prevent a code segment from reaching customers when an organization is using Continuous Deployment. Feature flags used for this purpose are also called release flags. However, feature flags can be used for other purposes. One example is creating different versions of the same software. For instance, consider a system with a free and a paid version. Customers of the paid version have access to more features, and this access is controlled by feature flags. In this specific case, these flags are called business flags.
Bibliography 🔗
Gene Kim, Jez Humble, John Willis, Patrick Debois. The DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations. IT Revolution Press, 2016.
Jez Humble, David Farley. Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation. Addison-Wesley, 2010.
Paul Duvall, Steve Matyas, Andrew Glover. Continuous Integration: Improving Software Quality and Reducing Risk. Addison-Wesley, 2007.
Exercises 🔗
1. Define and describe the objectives of DevOps.
2. Job offers in the IT sector often mention openings for a DevOps
Engineer
, requiring skills such as:
- Version control tools (Git, Bitbucket, SVN, etc.)
- Dependency and build managers (Maven, Gradle, etc.)
- Continuous Integration tools (CircleCI, GitHub Actions)
- Cloud server administration (AWS, Azure)
- Operating systems (Ubuntu, CentOS, and Red Hat)
- Databases (DynamoDB, MySQL)
- Docker and container orchestration (Kubernetes, Mesos, Swarm)
- Development via REST APIs and Java
Based on your definition of DevOps from the previous question, assess whether it is appropriate to designate this role as a DevOps Engineer. Justify your answer.
3. Describe two advantages of using a Distributed Version Control System (DVCS).
4. Identify a disadvantage associated with the use of monorepositories.
5. Define and differentiate among the following terms: Continuous Integration, Continuous Delivery, and Continuous Deployment.
6. Explain the importance of Continuous Integration, Continuous Delivery, and Continuous Deployment in DevOps practices. Relate your answer to the definition of DevOps that you provided in the first question of this list.
7. Research the meaning of the term CI Theater
. Then, define
it in your own words.
8. Imagine you are hired by a company to establish DevOps practices for the development of printer drivers. Would you implement Continuous Deployment or Continuous Delivery? Justify your answer.
9. Identify a problem (or challenge) that arises when using feature flags to control code that is not ready for production.
10. Programming languages such as C support conditional compilation
directives like #ifdef and #endif. Research
their functionality and usage. Compare and contrast them with feature
flags.
11. Compare the typical lifespan of release flags and business flags in code. Which tends to persist longer? Justify your answer.
12. When companies migrate to CI, they often abandon feature branches in favor of a single, shared branch. This practice is called Trunk-Based Development (TBD), as discussed in this chapter. However, TBD does not mean that branches are never used in these companies. Describe an alternative use for branches unrelated to feature implementation.
13. Read the following article from the official Gmail blog, which describes a major interface update made in 2011. The article compares the challenges of this migration to those of changing the tires of a car while it is moving. Based on this article, answer:
Identify the key technology discussed in this chapter that enabled the Gmail interface update. How does the article refer to this technology?
What term do we use in this chapter to describe this technology?