
Software Engineering: A Modern Approach
1 What is a Serverless Architecture?
1.1 Introduction
In this article, we describe the concept of serverless architectures, which are increasingly being adopted by software companies.
We begin by describing the historical context, since to understand the concept of serverless it is helpful to first recall the evolution of hardware infrastructures over the last decades. Next, we introduce the concept of serverless functions and provide an example. Finally, we discuss some disadvantages of this architectural style.
1.2 History
Until the 1990s, companies had to buy physical servers to host their systems. They also needed physical spaces, referred to as data centers, to accommodate them. Currently, this model is also known as on-premises because the servers are installed on the company’s own buildings or properties.
Next, during the 1990s, data centers for hosting servers of other organizations began to emerge. This change eliminated the need for having dedicated spaces to install machines and, consequently, the need to worry about electrical installations, climate control, uninterruptible power supplies, Internet access, and physical access control to machines. These data centers are called colocation, as servers from several companies share the same installations.
Then, in the early 2000s, cloud platforms appeared offering virtual servers to contracting companies. As a result, the purchase of physical servers was no longer mandatory. Cloud providers assumed this responsibility by providing virtual servers that run on top of their physical machines.
The concept of serverless can be seen as the next evolution in this process. Basically, an organization demanding a system implements a set of functions—typically called serverless functions or lambda functions—and installs them in a cloud platform. Therefore, there is no payments for servers, whether they are virtual or physical. The serverless functions can be invoked by client applications or they are called automatically upon the occurrence of certain events.
The next figure compares these alternatives for application hosting.
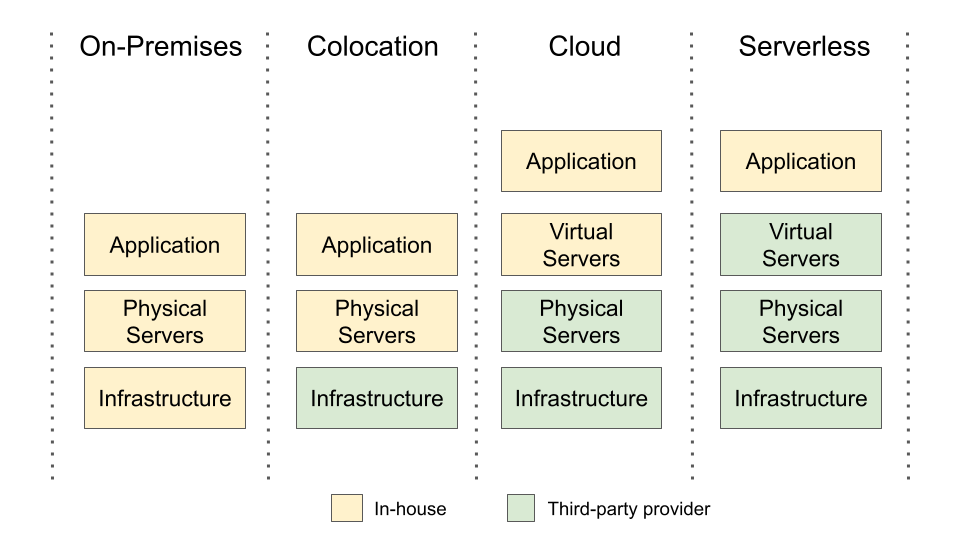
The name serverless derives from the fact that customers do not need to concern themselves with installation, configuration, and scalability of servers, whether they are physical or virtual. In other words, the servers still exist, but they are maintained and configured by cloud companies.
1.3 Pricing Model
With serverless, you pay for the execution time of the serverless functions. That is, you only pay when the function is used.
This payment model is similar to the one of utility services, like electricity. For example, you only pay for what you use in electricity. If there is no use in a month, your bill will be zero or equal to a minimum amount. If you need to increase your consumption, within certain limits, the electricity company automatically provides you the extra supply.
However, even though you’re not paying for idle time, a serverless solution is not necessarily cheaper than a serverful one. The definition of the cheapest model depends on the prices charged by the cloud provider for executing serverless functions and for renting virtual servers. It also depends on the price of buying physical servers and maintaining them in data centers or colocation spaces.
1.4 Serverless Functions
Serverless functions have the following characteristics:
They are stateless, i.e., they don’t retain any state between executions. However, they can access external services, like databases and email services.
They run for a maximum time interval, usually on the order of a few minutes. After this interval, they are automatically terminated by the cloud platform.
They can be implemented in a variety of programming languages.
Example
Netlify is a cloud company that offers a serverless service. Next, we show an example of a serverless function for this platform:
exports.handler = async (event, context) => {
return {
statusCode: 200,
body: "Hello, World"
};
};As you can see, the function returns an object with two fields: the
first is the status code of the call, in this case equal to 200, which
signals that the request was processed successfully; the second is the
body of the response, which corresponds to the string Hello,
World
.
You can call this function using the following URL:
https://functions.netlify.com/.netlify/functions/hello
In conclusion, to implement a serverless architecture, you should implement a set of functions similar to the one we’ve just shown and copy them to your account in a cloud provider.
You can find other examples of serverless functions on this page.
1.5 Conclusion
To explain the benefits of serverless, the authors of an article published in May 2021 in the Communications of the ACM magazine make an interesting comparison between this type of architecture and programming languages:
Just as high-level languages hide many details of how a CPU operates, serverless computing hides many details of what it takes to build a reliable, scalable, and secure distributed system.
However serverless architecture also has disadvantages, such as:
The complexity of managing an architecture made up of a large number of small functions. Each serverless function is an autonomous application, in the sense that it must import all dependencies necessary for its execution. This includes third-party libraries and also other application modules, like domain modules.
The higher latency, especially on the first execution of a serverless function. This latency is due to the need to create a container to run the function. The literature refers to this issue as the cold start problem, since it is more critical on the first execution of a function. Afterwards, the container can be kept on cache at least for some time.
The risks of ending up with a high coupling with the cloud platform, making it more challenging to switch to a different provider. This problem is called vendor lock-in. Looking at the example function above, this problem may not be clear, as this function looks like a regular JavaScript function. However, vendor lock-in becomes more critical when have many functions using services offered by the platform, like authentication, message queues, logging, and databases.
Before we conclude, it’s important to note that it is also possible to have a hybrid architecture in which only specific services are implemented using serverless functions.
Exercises
1. When we use serverless, we don’t need to worry about the issues below, EXCEPT:
- Capacity planning
- Load balancing
- Scalability
- Fault tolerance
- Persistence
2. Why should the term serverless not be taken literally, that is, as
synonymous with computing without servers
?
3. Assume a Todo app built using a serverless architecture. Next, we show one function of this application, which returns all tasks saved in the app (this function was copied from the following repository). What disadvantage, as discussed in Section 1.5, becomes clear when we analyze this function? Justify your answer.
'use strict';
const AWS = require('aws-sdk');
const dynamoDb = new AWS.DynamoDB.DocumentClient();
module.exports = (event, callback) => {
const params = {
TableName: 'todos',
};
return dynamoDb.scan(params, (error, data) => {
if (error) {
callback(error);
}
callback(error, data.Items);
});
};4. Analyze and study the sequence diagrams shown in Figures 1 and 2 on page 4 of the following article. They are from an application that was initially implemented using a monolithic architecture (Figure 1) and then it was migrated to use serverless functions (Figure 2). Essentially, the functionality represented in the diagrams allows a user to upload a file and request its conversion to another format (pdf, svg, etc). Then, answer:
Which of the diagrams is simpler and easier to understand? Justify your answer.
Describe one major difference between the two diagrams. That is, describe a relevant change made in the original architecture (Figure 1) to make it suitable for a serverless solution (Figure 2). Justify your answer.
Check out the other articles on our site.